特征列
本篇文档将详细介绍特征列。特征列可以视为原始数据和 Estimator 间的中介。特征列非常丰富,可以让你将各种不同的原始数据转化为 Estimator 可用的格式,从而轻松的进行实验。
tf.feature_column.numeric_column
现实世界中,一些的特征(例如经度)是数字的,但是很多(特征)并不是(数字的)。
输入至深度神经网络
深度神经网络可以操作什么样的数据?答案当然是数字(例如,tf.float32)。毕竟,神经网络的每个神经元都会对权重和输入值进行乘法和加法操作。但是,现实中的输入数据经常包含非数字的(分类的)数据。例如,一个 product_class 特征就可能包含如下三个非数字的值:
- 厨具
- 电子产品
- 运动产品
机器学习模型通常都会以简单的向量代表分类值,在向量中,1 表示某值存在,0 表示值不存在。例如,当 product_class 运动产品的集合时,一个机器学习模型通常会以 [0, 0, 1] 表示 product_class ,含义是:
0: 厨具不存在0: 电子产品不存在1: 运动产品存在
所以,尽管原始数据可能是数字或者分类,机器学习模型都要以数字表示所有的特征。
特征列
如下图所示,您可以通过 Estimator(鸢尾花模型使用了 DNNClassifier )的 feature_columns 参数指定模型的输入。特征列桥接输入数据(由 input_fn 返回的数据)和模型。
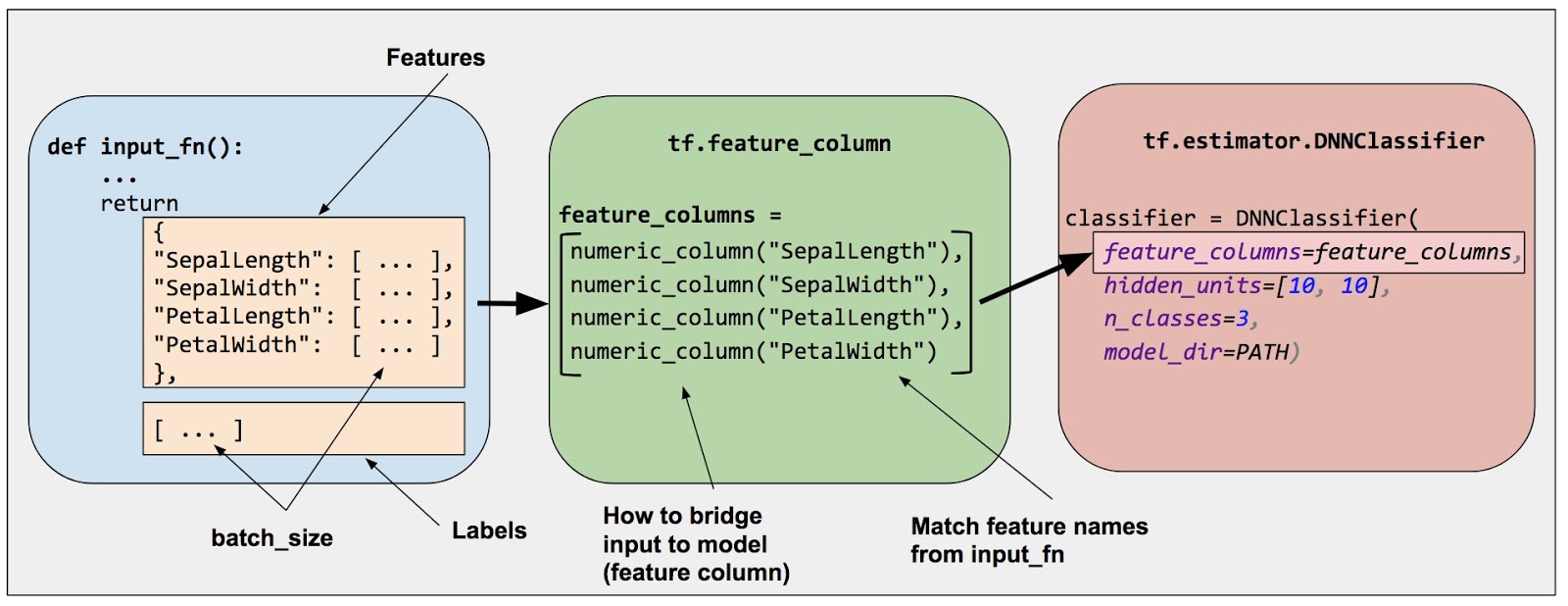
特征列将原始数据和模型需要的数据桥接起来。
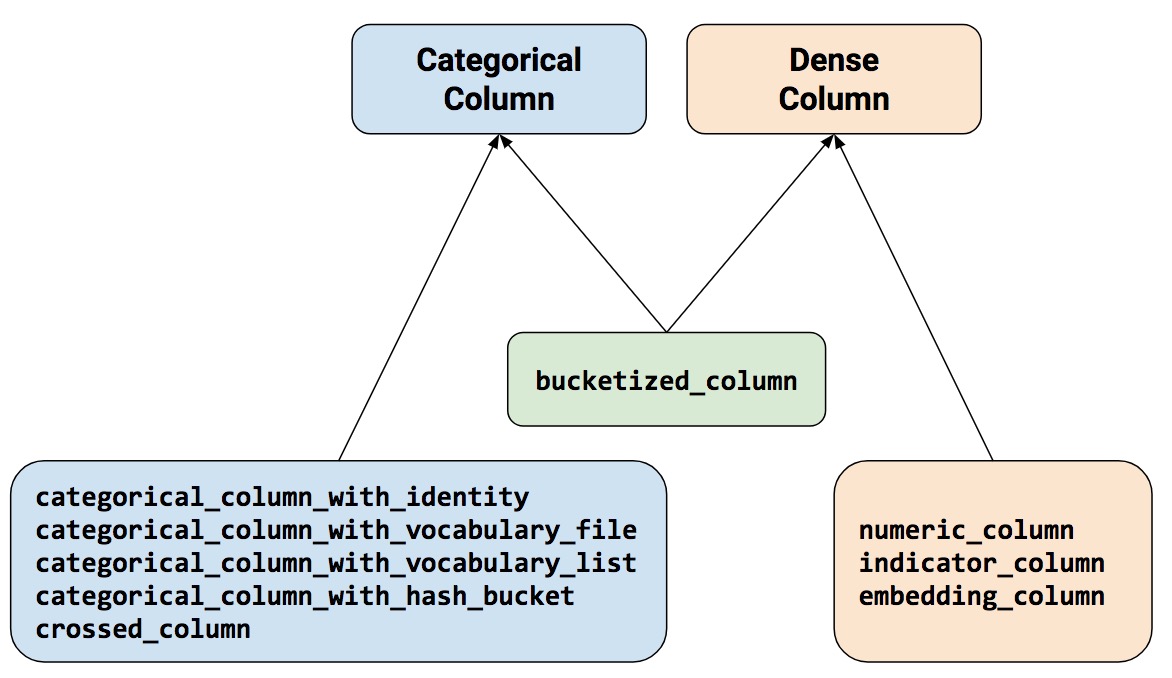
特征列方法分为两个主类和一个混合类。
下面让我们更具体的了解这几个方法。
数值列
tf.feature_column.numeric_column
SepalLength(萼片长度)SepalWidth(萼片宽度)PetalLength(花瓣长度)PetalWidth(花瓣宽度)
虽然 tf.numeric_column 提供了可选的参数,但是像如下所示这样,不带任何参数的调用它却是一个不错的方式,这样可以用默认的数据类型(tf.float32)来指定模型输入的数值。
# 默认为 tf.float32 标量。
numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength")
如果想指定非默认的数据类型,可以定义 dtype 参数。例如:
# 代表 tf.float64 标量。
numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength",
dtype=tf.float64)
默认情况下,一个数值列仅创建一个值(标量)。使用 shape 参数来定义数据维度。例如:
```python # 代表一个 10 元素的向量,每个元素中包含一个 tf.float32 类型的值。 vector_feature_column = tf.feature_column.numeric_column(key="Bowling", shape=10) # 代表一个 10x5 矩阵,矩阵中每个元素中包含一个 tf.float32 类型的值。 matrix_feature_column = tf.feature_column.numeric_column(key="MyMatrix", shape=[10,5]) ``` ### 分桶列 通常情况下,我们不希望直接将数值传入模型,而是根据取值范围将数值放进不同的类别中。可以通过创建 @{tf.feature_column.bucketized_column$bucketized column} 完成上述功能。例如,考虑一组表示房屋建成年份原始数据。我们应该将年份放入 4 个不同的 buckets 中,而不是把每一个年份数值都作为一个标量数值列: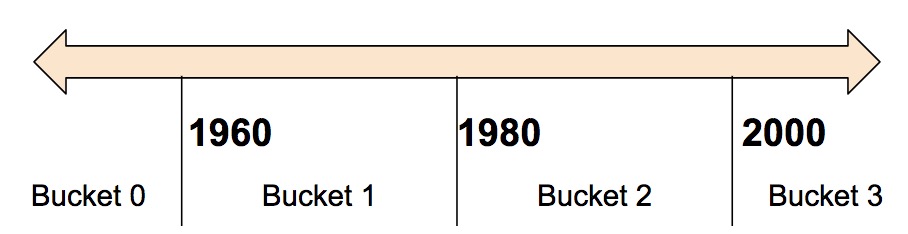 将年份数据分散到四个 buckets 中。
模型将按照如下表格表示 buckets:
|时间范围 |表示方法 |
|:----------|:-----------------|
|< 1960 | [1, 0, 0, 0] |
|>= 1960 but < 1980 | [0, 1, 0, 0] |
|>= 1980 but < 2000 | [0, 0, 1, 0] |
|> 2000 | [0, 0, 0, 1] |
为什么要把可以完美输入到模型中的数值分散到表示不同范围的类别呢?我们注意到,分类后,数值变成了一个四元素向量,因此现在模型可以学习**四个独立的权值**而不是从前的一个;四个权值能比一个权值创建出更丰富的模型。更重要的是,分桶操作让模型能更清晰的区分不同的年份类,因为向量中仅有一个元素置 (1) 而其他都是 (0)。例如,当我们只用一个年份数值作为输入的时候,一个线性模型只能学习线性关系。这样看来,分桶操作为模型提供了附加的灵活性,模型可以基于此进行学习。
下面的代码详述了如何创建 bucketized 特征。
```python
# 第一步,将原始输入转化为数值列 numeric column。
numeric_feature_column = tf.feature_column.numeric_column("Year")
# 接下来,以年份 1960、1980 和 2000 作为边界,将数值列分桶。
bucketized_feature_column = tf.feature_column.bucketized_column(
source_column = numeric_feature_column,
boundaries = [1960, 1980, 2000])
```
注意,一个**三**元素的边界向量将会创建**四**元素的分桶向量。
### 分类标识列
**分类标识列(Categorical identity columns)** 可以被看作分桶列的一个特殊实例。传统的分桶列中,每一个 bucket 代表一个范围的数值(例如,从 1960 到 1979)。在分类标识列中,每一个 bucket 则代表了一单一、独立的整数。例如,你想要表示一个在 `[0, 4)` 范围内的整数,也就是 0、1、2 或者 3。这时,分类标识的映射如下所示:
将年份数据分散到四个 buckets 中。
模型将按照如下表格表示 buckets:
|时间范围 |表示方法 |
|:----------|:-----------------|
|< 1960 | [1, 0, 0, 0] |
|>= 1960 but < 1980 | [0, 1, 0, 0] |
|>= 1980 but < 2000 | [0, 0, 1, 0] |
|> 2000 | [0, 0, 0, 1] |
为什么要把可以完美输入到模型中的数值分散到表示不同范围的类别呢?我们注意到,分类后,数值变成了一个四元素向量,因此现在模型可以学习**四个独立的权值**而不是从前的一个;四个权值能比一个权值创建出更丰富的模型。更重要的是,分桶操作让模型能更清晰的区分不同的年份类,因为向量中仅有一个元素置 (1) 而其他都是 (0)。例如,当我们只用一个年份数值作为输入的时候,一个线性模型只能学习线性关系。这样看来,分桶操作为模型提供了附加的灵活性,模型可以基于此进行学习。
下面的代码详述了如何创建 bucketized 特征。
```python
# 第一步,将原始输入转化为数值列 numeric column。
numeric_feature_column = tf.feature_column.numeric_column("Year")
# 接下来,以年份 1960、1980 和 2000 作为边界,将数值列分桶。
bucketized_feature_column = tf.feature_column.bucketized_column(
source_column = numeric_feature_column,
boundaries = [1960, 1980, 2000])
```
注意,一个**三**元素的边界向量将会创建**四**元素的分桶向量。
### 分类标识列
**分类标识列(Categorical identity columns)** 可以被看作分桶列的一个特殊实例。传统的分桶列中,每一个 bucket 代表一个范围的数值(例如,从 1960 到 1979)。在分类标识列中,每一个 bucket 则代表了一单一、独立的整数。例如,你想要表示一个在 `[0, 4)` 范围内的整数,也就是 0、1、2 或者 3。这时,分类标识的映射如下所示:
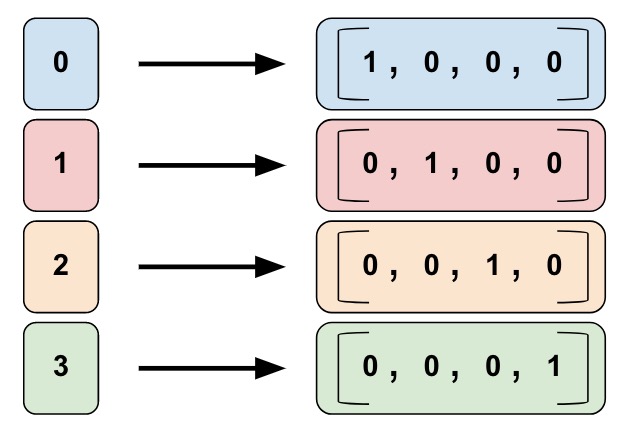 一个分类标识列的映射。注意,这是独热编码,而不是二进制数字编码。
和分桶列一样,模型能够从每个分类标识列的分类中学习单独的权重。如下所示,我们用唯一的数字而不是字符串来代表 `product_class` 中的值:
* `0="厨具"`
* `1="电子产品"`
* `2="运动产品"`
调用 @{tf.feature_column.categorical_column_with_identity} 方法来应用分类标识列,例如:
``` python
# 创建一个名为 "my_feature_b" 的整数特征的分类输出,
# my_feature_b 中的数值必须 >= 0 并且 < num_buckets
identity_feature_column = tf.feature_column.categorical_column_with_identity(
key='my_feature_b',
num_buckets=4) # 取值范围:[0, 4)
# 为了前面一段代码的调用能够生效,input_fn() 方法必须返回一个包含 'my_feature_b' 作为 key 值的字典。
# 并且,'my_feature_b' 对应的值必须属于集合 [0, 4)。
def input_fn():
...
return ({ 'my_feature_a':[7, 9, 5, 2], 'my_feature_b':[3, 1, 2, 2] },
[Label_values])
```
### 分类词汇列
我们不能将字符串直接作为模型的输入值。我们必须首先将字符串对应为数字或分类的值。分类词汇列(Categorical vocabulary columns)提供了一个不错的用独热向量来代表字符串的方式。例如:
一个分类标识列的映射。注意,这是独热编码,而不是二进制数字编码。
和分桶列一样,模型能够从每个分类标识列的分类中学习单独的权重。如下所示,我们用唯一的数字而不是字符串来代表 `product_class` 中的值:
* `0="厨具"`
* `1="电子产品"`
* `2="运动产品"`
调用 @{tf.feature_column.categorical_column_with_identity} 方法来应用分类标识列,例如:
``` python
# 创建一个名为 "my_feature_b" 的整数特征的分类输出,
# my_feature_b 中的数值必须 >= 0 并且 < num_buckets
identity_feature_column = tf.feature_column.categorical_column_with_identity(
key='my_feature_b',
num_buckets=4) # 取值范围:[0, 4)
# 为了前面一段代码的调用能够生效,input_fn() 方法必须返回一个包含 'my_feature_b' 作为 key 值的字典。
# 并且,'my_feature_b' 对应的值必须属于集合 [0, 4)。
def input_fn():
...
return ({ 'my_feature_a':[7, 9, 5, 2], 'my_feature_b':[3, 1, 2, 2] },
[Label_values])
```
### 分类词汇列
我们不能将字符串直接作为模型的输入值。我们必须首先将字符串对应为数字或分类的值。分类词汇列(Categorical vocabulary columns)提供了一个不错的用独热向量来代表字符串的方式。例如:
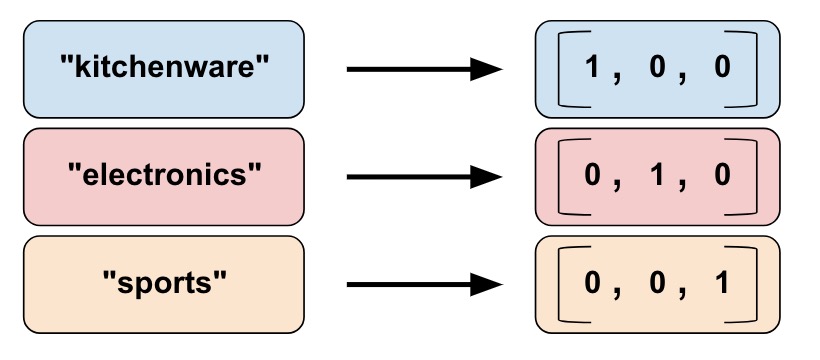 将字符串映射为词列。
如你所见,分类词汇列(Categorical vocabulary columns)是分类标识列(Categorical identity columns)的一种枚举版本。TensorFlow 提供了如下两个不同的方法来建立是分类标识列:
* @{tf.feature_column.categorical_column_with_vocabulary_list}
* @{tf.feature_column.categorical_column_with_vocabulary_file}
`categorical_column_with_vocabulary_list` 方法基于一个分类的词汇列表,将每个字符串映射为一个整数。例如:
```python
# 给定输入 "feature_name_from_input_fn" 是一个字符串,通过将输入映射为词典列表的一个元素可以创建一个分类特征。
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_list(
key=feature_name_from_input_fn,
vocabulary_list=["kitchenware", "electronics", "sports"])
```
前面这个方法很简单,但它有一个严重的缺点。也就是说,当词汇列表很长的时候,对应的类就太多了。这种情况下应调用方法 `tf.feature_column.categorical_column_with_vocabulary_file`,它允许你将词汇放置在一个单独的文件里。例如:
```python
# 给定输入 "feature_name_from_input_fn" 是一个字符串,通过将输入映射为词汇文件里的一个元素可以为模型创建一个分类特征。
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_file(
key=feature_name_from_input_fn,
vocabulary_file="product_class.txt",
vocabulary_size=3)
```
`product_class.txt` 应当每一行包含一个词汇元素,在我们的实例中:
```None
kitchenware
electronics
sports
```
### 哈希列
目前为止,我们只讨论了类数目很少的实例。例如,product_class 实例只有三个类目。但是通常情况下,类的数量很大,以至于不可能每一个词或者整数都有一个独立的分类,因为如果这样内存开销将会过大。在这种情况下,我们可以反过来思考这个问题:我愿意将输入分为多少个类别?事实上,@{tf.feature_column.categorical_column_with_hash_bucket} 方法允许你定义分类的数目。对于这种类型的特征列,模型会计算输入的哈希值,然后使用模运算符将这个值放入一个 `hash_bucket_size` 类中,如下伪代码所示:
```python
# 伪代码
feature_id = hash(raw_feature) % hash_buckets_size
```
代码创建的 `feature_column` 也许是这样:
``` python
hashed_feature_column =
tf.feature_column.categorical_column_with_hash_bucket(
key = "some_feature",
hash_buckets_size = 100) # 分类数目
```
此时,你理所当然可能会想:这太疯狂了!毕竟,我们强制把不同的输入值变为一个较小的分类集合。这意味着两个可能不相关的输入将会被映射到一个类中,因此也就意味着在神经网络中会发生同样的事情。下图详细说明了这个进退两难的困境,可以看到,厨具和运动产品都被分类到了类别(哈希桶)12:
将字符串映射为词列。
如你所见,分类词汇列(Categorical vocabulary columns)是分类标识列(Categorical identity columns)的一种枚举版本。TensorFlow 提供了如下两个不同的方法来建立是分类标识列:
* @{tf.feature_column.categorical_column_with_vocabulary_list}
* @{tf.feature_column.categorical_column_with_vocabulary_file}
`categorical_column_with_vocabulary_list` 方法基于一个分类的词汇列表,将每个字符串映射为一个整数。例如:
```python
# 给定输入 "feature_name_from_input_fn" 是一个字符串,通过将输入映射为词典列表的一个元素可以创建一个分类特征。
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_list(
key=feature_name_from_input_fn,
vocabulary_list=["kitchenware", "electronics", "sports"])
```
前面这个方法很简单,但它有一个严重的缺点。也就是说,当词汇列表很长的时候,对应的类就太多了。这种情况下应调用方法 `tf.feature_column.categorical_column_with_vocabulary_file`,它允许你将词汇放置在一个单独的文件里。例如:
```python
# 给定输入 "feature_name_from_input_fn" 是一个字符串,通过将输入映射为词汇文件里的一个元素可以为模型创建一个分类特征。
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_file(
key=feature_name_from_input_fn,
vocabulary_file="product_class.txt",
vocabulary_size=3)
```
`product_class.txt` 应当每一行包含一个词汇元素,在我们的实例中:
```None
kitchenware
electronics
sports
```
### 哈希列
目前为止,我们只讨论了类数目很少的实例。例如,product_class 实例只有三个类目。但是通常情况下,类的数量很大,以至于不可能每一个词或者整数都有一个独立的分类,因为如果这样内存开销将会过大。在这种情况下,我们可以反过来思考这个问题:我愿意将输入分为多少个类别?事实上,@{tf.feature_column.categorical_column_with_hash_bucket} 方法允许你定义分类的数目。对于这种类型的特征列,模型会计算输入的哈希值,然后使用模运算符将这个值放入一个 `hash_bucket_size` 类中,如下伪代码所示:
```python
# 伪代码
feature_id = hash(raw_feature) % hash_buckets_size
```
代码创建的 `feature_column` 也许是这样:
``` python
hashed_feature_column =
tf.feature_column.categorical_column_with_hash_bucket(
key = "some_feature",
hash_buckets_size = 100) # 分类数目
```
此时,你理所当然可能会想:这太疯狂了!毕竟,我们强制把不同的输入值变为一个较小的分类集合。这意味着两个可能不相关的输入将会被映射到一个类中,因此也就意味着在神经网络中会发生同样的事情。下图详细说明了这个进退两难的困境,可以看到,厨具和运动产品都被分类到了类别(哈希桶)12:
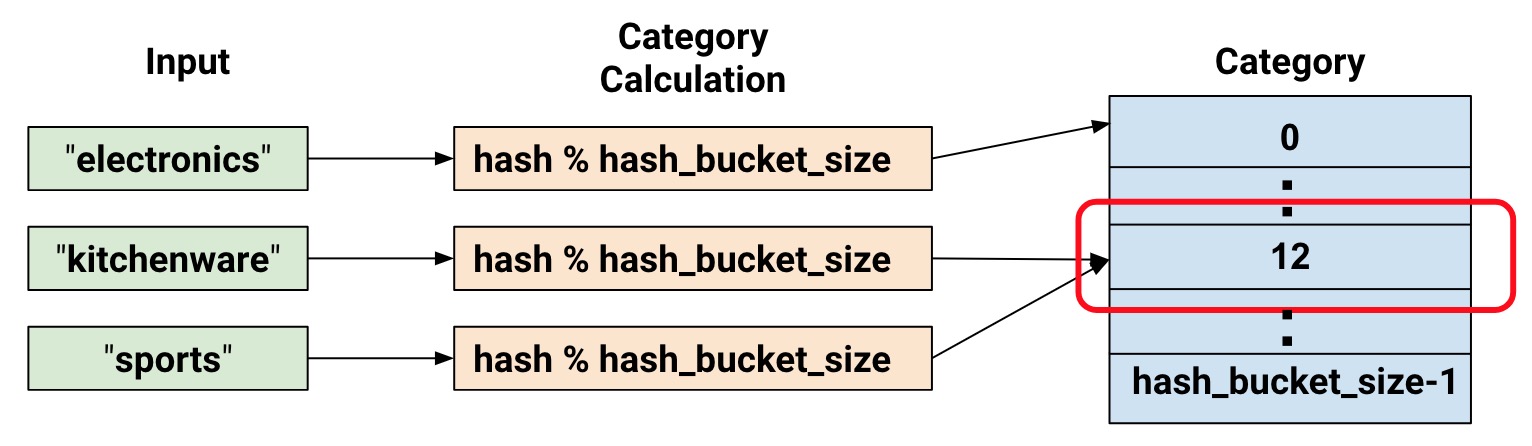 使用哈希桶来表示数据。
与机器学习中的许多违反直觉的现象一样,事实表明哈希算法在实践中的表现很好。这是因为哈希分类为模型提供了一些离散特性。模型可以使用附加特征来进一步将厨具和运动产品分离。
### 交叉列
将多特征融合为一个,也就是更广为人知的 [feature crosses](https://developers.google.com/machine-learning/glossary/#feature_cross),让模型能够为每个合成特征学习单独的权重。
更具体说来,假如我希望模型计算亚特兰大房地产价格。由于位置不同,城市内房地产价格差别很大。将纬度和经度表示为单独的特征在识别房地产位置依赖性方面并不是非常有用;然而,将纬度和经度交叉成单个特征可以精确定位位置。假设亚特兰大是一个 100×100 的矩形网格,并通过纬度和经度的交叉特征识别这 10,000 个部分中的每一个。这样的特征交叉让模型可以在每个独立部分的价格条件下进行训练,这比单独使用经度或者纬度都要强健。
下图展示了上述计划,以红色文本显示城市四角的纬度和经度值:
使用哈希桶来表示数据。
与机器学习中的许多违反直觉的现象一样,事实表明哈希算法在实践中的表现很好。这是因为哈希分类为模型提供了一些离散特性。模型可以使用附加特征来进一步将厨具和运动产品分离。
### 交叉列
将多特征融合为一个,也就是更广为人知的 [feature crosses](https://developers.google.com/machine-learning/glossary/#feature_cross),让模型能够为每个合成特征学习单独的权重。
更具体说来,假如我希望模型计算亚特兰大房地产价格。由于位置不同,城市内房地产价格差别很大。将纬度和经度表示为单独的特征在识别房地产位置依赖性方面并不是非常有用;然而,将纬度和经度交叉成单个特征可以精确定位位置。假设亚特兰大是一个 100×100 的矩形网格,并通过纬度和经度的交叉特征识别这 10,000 个部分中的每一个。这样的特征交叉让模型可以在每个独立部分的价格条件下进行训练,这比单独使用经度或者纬度都要强健。
下图展示了上述计划,以红色文本显示城市四角的纬度和经度值:
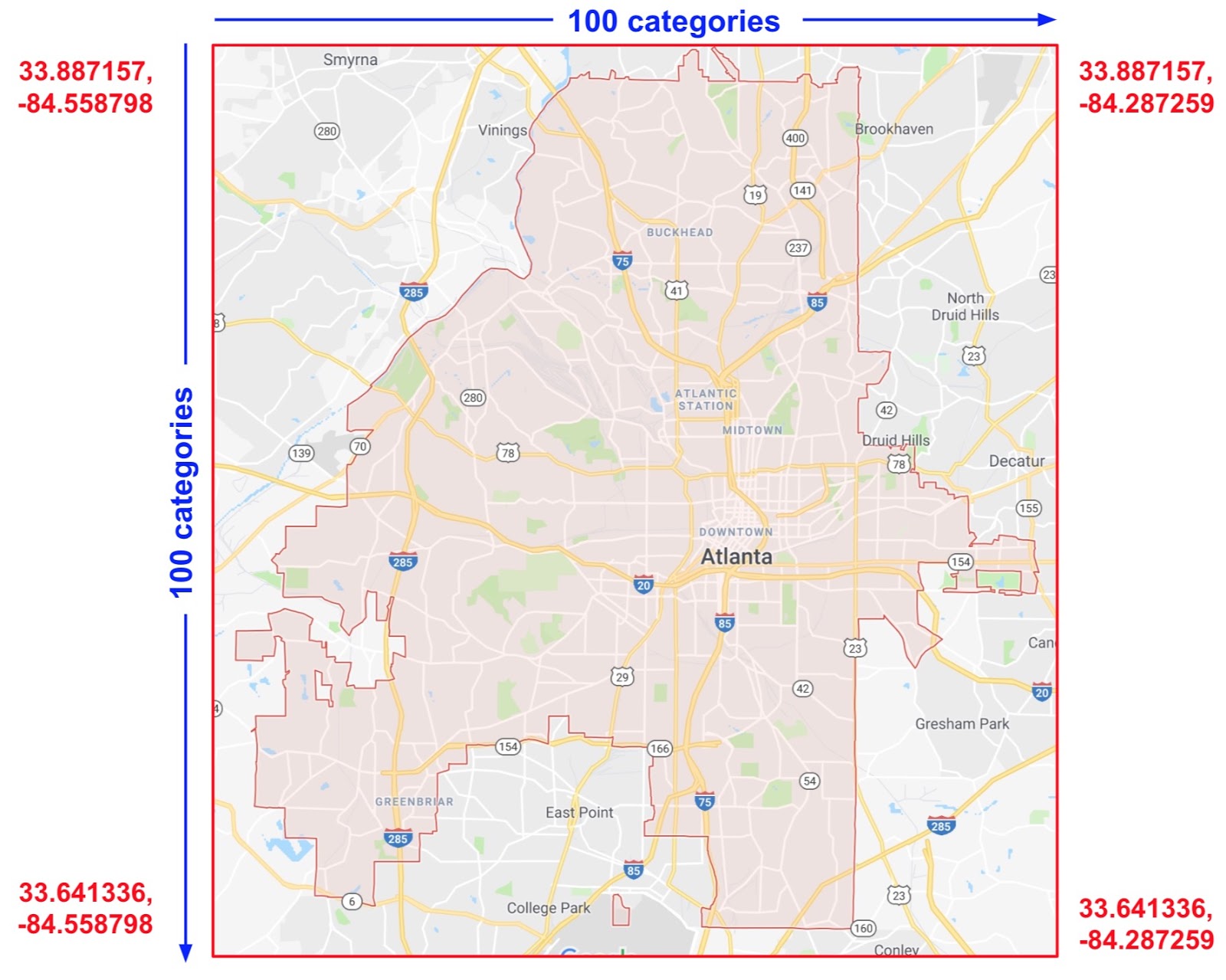 亚特兰大地图。想象这个地图被分为大小相同的 10,000 个部分。
下面的解决方案中,我们结合了前面提到的 `bucketized_column` 和方法 @{tf.feature_column.crossed_column}。
亚特兰大地图。想象这个地图被分为大小相同的 10,000 个部分。
下面的解决方案中,我们结合了前面提到的 `bucketized_column` 和方法 @{tf.feature_column.crossed_column}。
def make_dataset(latitude, longitude, labels):
assert latitude.shape == longitude.shape == labels.shape
features = {'latitude': latitude.flatten(),
'longitude': longitude.flatten()}
labels=labels.flatten()
return tf.data.Dataset.from_tensor_slices((features, labels))
# 使用 `edges` 属性将经度和纬度分桶
latitude_bucket_fc = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column('latitude'),
list(atlanta.latitude.edges))
longitude_bucket_fc = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column('longitude'),
list(atlanta.longitude.edges))
# 使用 5000 个哈希箱将分桶列 bucketized columns 交叉。
crossed_lat_lon_fc = tf.feature_column.crossed_column(
[latitude_bucket_fc, longitude_bucket_fc], 5000)
fc = [
latitude_bucket_fc,
longitude_bucket_fc,
crossed_lat_lon_fc]
# 建立并训练 Estimator。
est = tf.estimator.LinearRegressor(fc, ...)
你可以采用如下方法中的任何一个来创建一个交叉特征:
- 特征名;也就是,从
input_fn返回dict中的名字。 - 任意一个分类列,除了
categorical_column_with_hash_bucket(因为crossed_column散列了输入)。
特征列 latitude_bucket_fc 和 longitude_bucket_fc 交叉后,TensorFlow 将会为每个样本创建数据对 (latitude_fc, longitude_fc)。这将会产生如下这样的全量概率网格:
(0,0), (0,1)... (0,99)
(1,0), (1,1)... (1,99)
... ... ...
(99,0), (99,1)...(99, 99)
但不足是,完整的网格只适用于有限词汇表的输入。与此相比,crossed_column 仅创建 hash_bucket_size 参数规定的数字,而不是创建上面所示这样可能会很大的输入表。特征列通过在输入元组上运行哈希函数,为每个索引分配一个样本,接下来用 hash_bucket_size 进行模运算。
像我们前面讨论过的那样,运行哈希和模函数可以限制分类的数目,但是可能导致类别冲突;也就是,多个(纬度,经度)交叉特征将会最终属于同一个哈希桶。尽管如此,在实际应用中,采用特征交叉仍旧可以为模型的学习能力显著加分。
有点违背直觉的是,当创建交叉特征的时候一般仍旧需要在模型中包括原始(未交叉)特征(如前面的代码片段所示)。独立的经度和纬度信息帮助模型在交叉特征出现哈希碰撞的时候区分不同样本。
指针和嵌入列
指针列和嵌入列不直接作用于特征,它们将分类列作为输入值。
使用指针列时,我们就是在告诉 TensorFlow 去做分类产品样本一样的事。也就是,指针列将每一个类别当作一个独热向量的元素,这个向量中与结果匹配的类是 1,其他都是 0。
在指针列中表示数据。
tf.feature_column.indicator_column
categorical_column = ... # 创建一个任意类别的分类列。
# 将分类列表示为指针列。
indicator_column = tf.feature_column.indicator_column(categorical_column)
现在假设并不只有三个可能的类,而是有一百万个,甚至十亿个。出于很多原因,当类别的数目增长到很大的时候,使用指针类来训练神经网络就变的不可行了。
我们可以用嵌入列来克服这个限制。嵌入列用低维的普通矢量,而非多维度的独热向量来表示数据。普通矢量中每个元素可以包含任何数值,而不仅是 0 和 1。通过为每个元素提供更丰富的数字候选,嵌入列包含的元素数量远少于指标列。
让我们来看一个对比指针列和嵌入列的例子。假设输入样本包括来自仅有 81 个单词的有限候选集中的不同单词。进一步假设,数据集在 4 个单独的样本中提供如下的输入词:
"狗""勺子""剪刀""吉他"
在这个例子中,如下图所示说明了嵌入列和指针列的处理途径。
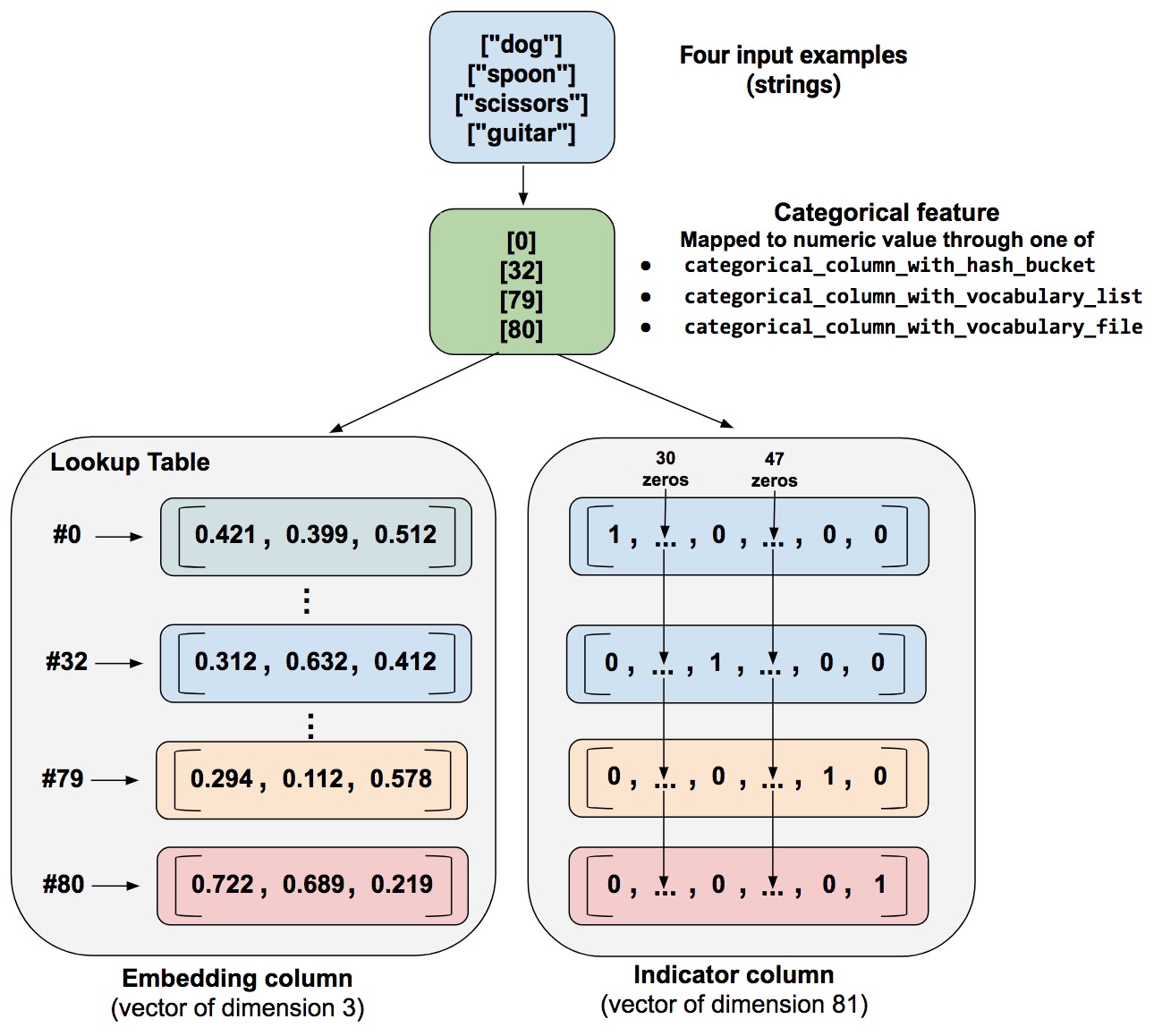
相比于指针列,嵌入列用维度较低的向量来存储分类数据。(我们只是将随机数放入了嵌入向量;训练决定真实的数字)
当一个样本被处理时,其中一个 categorical_column_with... 函数将样本字符串映射为数字的分类值。例如,一个方法将“勺子”映射为 [32]。(这里的 32 是我们假想的 - 实际值取决于映射函数。)接下来,你可以用如下两种方式来表示这些数字分类值:
指针列。一个将每个数字分类值转化为 81 元素向量的方法(因为候选集包含 81 个单词),将一个 1 放置在分类值的索引 (0, 32, 79, 80) 上,其余位置都是 0。
嵌入列。一个使用数字分类值
(0, 32, 79, 80)作为查找表索引的方法。在这个查找表里,每个元素包含一个三元素向量。
嵌入向量中的值是如何魔法般的被分配的呢?实际上,分配发生在训练期间。也就是,模型为了解决你的问题,学习了将输入的数字分类值映射为嵌入向量的最好方式。嵌入列提升了你的模型的能力,因为嵌入向量从训练数据中学到了分类之间的新的关系。
为什么在我们的实例中,嵌入向量的大小是 3?下面的“公式”提供了关于嵌入维数的一般规则
embedding_dimensions = number_of_categories**0.25
也就是,嵌入向量的维度应该是分类数量的开四次根号。既然本例中,词汇的大小是 81,那么推荐的维度数就是3。
3 = 81**0.25
注意这仅是一个一般准则,你可以将嵌入的维度设置为任何你喜欢的值。
tf.feature_column.embedding_column
categorical_column = ... # 创建任意的分类列
# 将分类列表示为嵌入列
# 这意味着要为每一个分类创建一个包含一个元素的独热向量
embedding_column = tf.feature_column.embedding_column(
categorical_column=categorical_column,
dimension=dimension_of_embedding_vector)
将特征列传递给 Estimator
如下列表所示,并不是所有 Estimator 都允许 feature_columns 参数的所有类别:
tf.estimator.LinearRegressortf.estimator.DNNRegressortf.estimator.DNNLinearCombinedRegressorlinear_feature_columns参数接受所有特征列类型。dnn_feature_columns参数只接受稠密列。
其他知识源
更多特征列的实例,参见如下:
学习更多和嵌入相关的知识,参见如下:
- Deep Learning, NLP, and representations
(Chris Olah 的博客) - The TensorFlow Embedding Projector
