准备用于部署到移动设备的模型
在训练时储存的模型与部署到手机应用上的模型在需求上是很不一样的。这篇文章介绍了在转换训练模型为生产模型时所用到的工具。
这些模型文件之间到底有什么区别?
有时候我们会困惑为什么 TensorFlow 保存模型的方法会有这么多,它们之间的区别是什么。为了帮助理解,下面简单地介绍了一部分不同组件用处。这些对象大多数借助协议缓冲区(protocol buffers)框架序列化的保存到文件里。
NodeDef: 定义了模型中一个单独的操作。它有唯一的名字,以及它拉取输入来源的其他节点的名称列表,结点所实现的操作类型(譬如
Add,或者Mul),控制该操作所需要的属性值。它是 TensorFlow 计算中的基础单元,所有的任务都是通过逐个迭代网络中的这些节点来完成的。有一个特别的操作是我们需要知道的,那就是Const,它包含的信息是一个常量。Const操作可以是一个数值或者字符串,甚至它可以保存一个多维的张量数组。Const的值是储存在NodeDef里面的,所以一个大的常量会在序列化后会占据较大的空间。Checkpoint:通过使用
Variable操作,我们也可以保存模型中的值。与Const操作不同的是,它不需要以NodeDef的形式保存,所以只占用GraphDef文件中很少的空间。在训练网络和更新权重时,Variable的值在计算运行时保存在内存中,然后定期作为检查点文件保存到磁盘。这是一个时序要求严格的操作,当使用分布式架构来训练模型的时候,多个 worker 会在不同的时间点要求执行该操作,因此储存模型的文件格式必须能够被快速读取且具备一定的扩展性。模型将会保存成多个检查点文件,与用来描述检查点都保存了什么信息的元文件。当你在 API 中引用检查点文件时(譬如说当你将检查点文件名当参数传递给命令行),你将会用到文件的前缀来引用相关联的文件,例如:
/tmp/model/model-chkpt-1000.data-00000-of-00002
/tmp/model/model-chkpt-1000.data-00001-of-00002
/tmp/model/model-chkpt-1000.index
/tmp/model/model-chkpt-1000.meta
你可使用 `/tmp/model/chkpt-1000` 来引用他们。
GraphDef:保存着
NodeDefs列表,定义着计算图是如何被运行的。在训练中,有一些节点可能是Variables,所以如果你想要一个完整的可运行的图,也即包含权重的,您需要调用恢复操作从检查点文件中提取这些值。检查点文件的格式设计的很灵活以至于能够满足我们训练的所有要求,通过一些技巧来移植模型到手机或其他嵌入设备内,尤其是像 iOS 设备那种具备特殊文件系统的。脚本freeze_graph.py就是用来生成一个完整的可运行的图的。上面我们讲解过,Const操作是作为NodeDef中的值储存的,因此如果将所有的Variable转换成Const节点的话,那么一个单独的GraphDef文件就已经包含了模型的结构和权重了。冻结网络的流程包含加载检查点文件,转换Variables为Consts这两个过程。然后您便可以抛弃检查点文件,单独调用 GraphDef 文件来加载模型了。需要注意的是有时候GraphDef文件会被保存为文本的格式以便我们查看里面的值,这种情况下文件后缀为.pbtxt,否则后缀为.pb。FunctionDefLibrary:在
GraphDef中出现,实际上是一组子图,每个子图都有关于它们的输入和输出节点的信息。每个子图可以被用作主图中的操作,类似于用函数封装其他语言的代码,提供便利的实例化方式。MetaGraphDef:纯
GraphDef只包含计算图的信息,但是没有关于模型的更多额外的信息,也没有关于模型如何被使用的信息。MetaGraphDef中包含了GraphDef,它定义了模型中的计算部分,包括调用模型时输入和输出的“签名”信息,数据和检查点文件在哪里和怎么样保存,以及标签信息方便分组操作。SavedModel:有时候,不同版本的图会依赖于一组通用的变量检查点。举个例子,您可能会让 CPU 和 GPU 都持有一个相同的图,并且要求它们的权重值保持一致。您的模型也可能需要一些额外的文件(例如标签的名字)。SavedModel 格式的文件可以解决这些需求,它能让你保存相同图的多个版本而不重复变量,另外额外的文件也会捆绑的保存在一起。这种格式的应用场景之一是用 TensorFlow Serving 部署 web API。
如何得到一个在手机上用的模型?
在大多数情况下,用 TensorFlow 训练的模型都会输出一个文件夹,里面包含了 GraphDef 文件(通常文件后缀是 .pb 或 .pbtxt)和检查点文件。手机和嵌入式设备需要的只是一个「冻结」的 GraphDef 文件,它已经将图中的变量转换为内联的常量。为了实现这个转换,你需要使用 freeze_graph.py 脚本,它在仓库的位置是 tensorflow/python/tools/freeze_graph.py。运行命令的例子如下:
bazel build tensorflow/tools:freeze_graph
bazel-bin/tensorflow/tools/freeze_graph \
--input_graph=/tmp/model/my_graph.pb \
--input_checkpoint=/tmp/model/model.ckpt-1000 \
--output_graph=/tmp/frozen_graph.pb \
--output_node_names=output_node \
input_graph 参数指向 GraphDef 文件,它包含了模型的架构。如果 GraphDef 文件是以文本的格式保存,也就是后缀是 .pbtxt 而不是 .pb 的话,你需要给命令添加额外的参数 --input_binary=false。
input_checkpoint 应该是最近一次保存的检查点文件。如上所述,你需要传递一个通用的前缀来引用它,而不是完整的文件名。
output_graph 定义了冻结的 GraphDef 文件会被保存在哪个路径下。因为它包含了很多的权重文件,用文本格式保存会占据较大空间,所以我们总是将它保存为二进制的协议缓冲区文件。
output_node_name 参数可以以列表的形式传递多个节点的名字,它代表了图的输出结果。这个参数告诉了脚本图中哪些节点的输出结果才是我们想要的,进而知道哪些是训练时的产物,譬如说 summarization 操作,只要那些对输出结果有贡献的节点才会被留下。在训练时传递给 Session::Run() 的节点名字一般都是你的图需要获取目标。我们在 python 中提供了相应的 api 能够简单的让你能够在构建图的时候视察节点的名字。当然用 Tensorboard 视察图结构也是一种很简便的方法。你可以通过运行 summarize_graph 工具 得到一些建议。
因为 TensorFlow 输出的格式是随时间变化的,所以在工具中存在其他很少用的参数,譬如 input_saver,但是幸运的是您在新版本的 TensorFlow 中训练时并不需要这些。
使用图转换工具
为了在嵌入设备上有效率的运行您的模型,您需要使用到图转换工具。该命令行工具接收 GraphDef 文件作为输入,提供了很多您可能会使用的重写规则,然后将返回的结果写到 GraphDef 文件中返回。下面介绍该工具如何构建和运行。
移除只在训练中用到的节点
TensorFlow 在训练中产生的 GraphDefs 文件包含了所有反向传播更新权重需要的计算,其中包含得到输入数据的队列,输入数据的解码,以及保存检查点。这些节点在推断的时候都是没有必要的,有些操作像保存检查点在移动平台上设置都是不支持的。为了创建在移动端加载的模型,您需要运行 strip_unused_nodes 规则来删除掉这些无用的操作。
这个过程中最棘手的部分就是要弄清楚在推断过程中哪些节点对应的名字是作为输入和输出的。输入输出节点的名字不仅在运行推断过程中会被用到,而且在转换过程中也需要根据它来判断推断的路径从而得知那些节点是不需要的。在 Tensorboard 中视察图结构是最容易得知这些节点的方法。
请记住,移动应用程序通常从传感器收集数据,并将其作为内存中的数组,但是训练过程通常涉及对储存在磁盘上的数据进行加载和解码。例如,在 Inception V3 的情况下,图的开始部分有一个 DecodeJpeg 操作,它设计的目的是将从磁盘检索到的文件中的 jpeg 编码数据转换成任意大小的图像。在此之后,有一个BilinearResize操作将其扩展到预期的大小,然后是其他一些操作,它们将字节数据转换为浮点数,并按图中其余部分所期望的方式缩放数值。一个典型的移动应用程序会跳过这些的步骤,因为它直接从摄像头中实时获得输入,所以你将提供的输入节点将是 Mul 节点的输出。
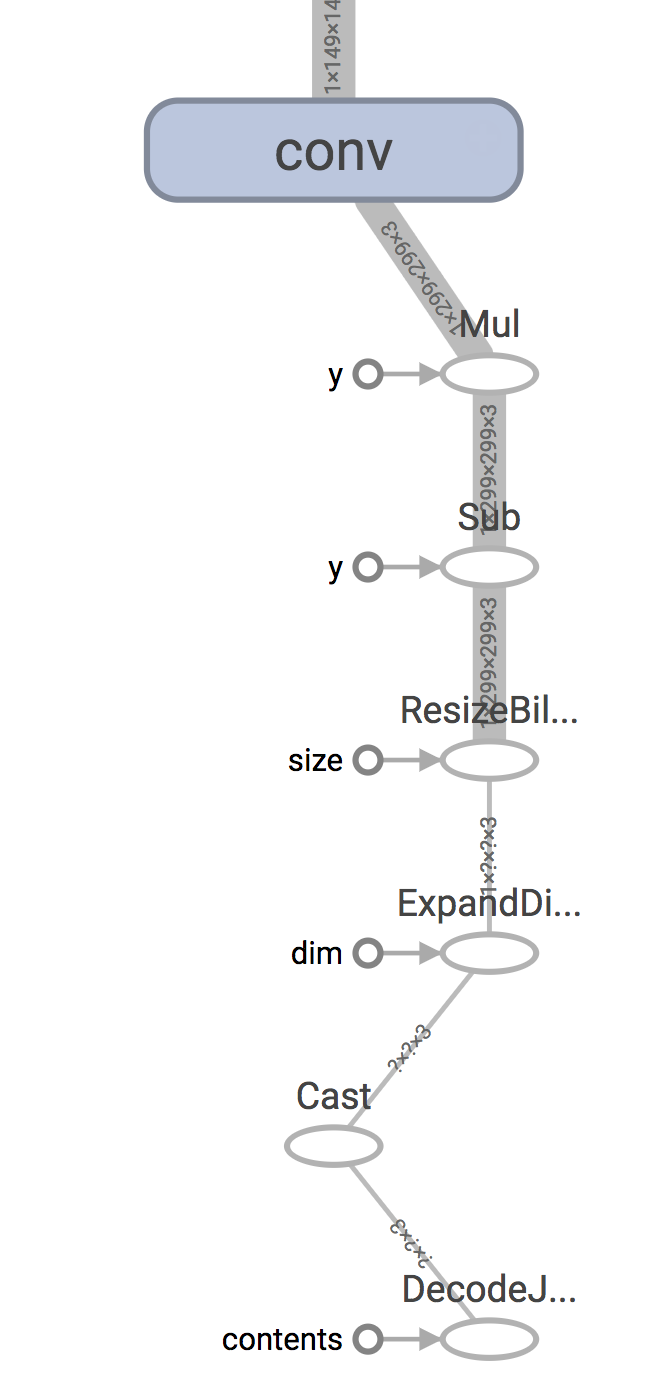
同样,你也需要做相同的操作来确认正确的输出节点。
如果你只给了一个冻结的 GraphDef 文件,但是不知道里面的结构,尝试使用 summarize_graph 工具得到图结构从而找到输入和输出。下面是 Inception V3 的一个例子:
bazel run tensorflow/tools/graph_transforms:summarize_graph --
--in_graph=tensorflow_inception_graph.pb
只要你清楚了输入和输出节点,那么您就可以将他们作为 --input_names 和 --output_names 的参数传递给图转换工具,并同时也调用 strip_unused_nodes 转换,如下所示:
bazel run tensorflow/tools/graph_transforms:transform_graph --
--in_graph=tensorflow_inception_graph.pb
--out_graph=optimized_inception_graph.pb --inputs='Mul' --outputs='softmax'
--transforms='
strip_unused_nodes(type=float, shape="1,299,299,3")
fold_constants(ignore_errors=true)
fold_batch_norms
fold_old_batch_norms'
这里需要注意的一点是,你需要指定输入的大小和类型。这是因为传递给模型推断的输入值都是要供给 Placeholder 操作节点的,如果该节点不存在转换工具会生成它。拿 Inception v3 举个例子,Placeholer 节点取代了旧的 Mul 节点来输出缩放图像数组,尽管我们会在调用 TensorFlow 之前做预处理。但它的节点名字没有改变,这也是为什么我们在运行修改后的图时总是将输入数据供给给 Mul 节点。
在您完成图转换后,得到的图将只包含预测过程所需要的节点。因此您可以再运行一次 summarize_graph 来了解您的模型都包含了什么。
什么操作应该包含在移动设备中?
TensorFlow 支持上百种不同的操作,而且针对不同的数据类型还有多种不同的实现。在移动平台上,为了能够获得最好的用户体验,通常情况下都会要求编译好的二进制可执行文件尽量的小。如果我们将所有的操作和数据类型都集成到 TensorFlow 库中的话,将会占据好几兆的空间,所以我们的依赖库只会包含一部分的操作和数据类型。
这意味着如果你在移动端加载 PC 机器上训练出来的模型文件,您可得到“该操作不支持”的错误信息。首先要做的是确保去掉了任何只在训练过程中用到的节点,因为即使没有执行操作,错误也会在加载模型时发生。如果您仍然遇到相同的问题,那么您需要考虑将该操作添加到构建的库中。
移动设备要包含的操作和类型主要有以下几类:
移动端只专注推断,因此在后向传播中计算梯度用到的操作和类型不需要包含。
它们如果用于其他的训练要求,譬如保存检查点,这些操作和类型也不需要包含。
如果依赖的操作在移动设备上不一定支持,我们也不需要包含。譬如说 libjpeg,我们可以通过不包含
DecodeJpeg操作来避免这种额外的依赖。是否有不常使用的类型?我们没有将布尔值包含进库里,因为我们发现该类型在推断图中不常使用。
定位操作在源码中的实现
操作将会被分为两部分。第一部分是操作的定义,里面声明了操作的签名,譬如输入,输出以及属性。这些只占据很小的空间,而且都是默认包含的。操作的计算和实现都是在内核中实现的,它在源码的路径是 tensorflow/core/kernels,通过添加 C++ 操作的实现,您可以编译自己需要的操作到库中。通过在源文件中搜索操作的名字,您可以找到您需要的文件。
您看到这个操作在寻找 Mul 操作的实现,并且发现它位于 tensorflow/core/kernels/cwise_op_mul_1.cc 中。您需要查找以 REGISTER 开头的宏,以及您所关系的操作名字的字符串。
在这种情况下,操作的实现可能会被拆分为多个 .cc 文件,因此您需要在构建中将他们都包含进来。如果您更习惯使用命令行来搜索代码,下面这个命令也可以帮助您定位到关联的文件,您只需要在 TensorFlow 仓库的根目录下运行下面的命令即可。
grep 'REGISTER.*"Mul"' tensorflow/core/kernels/*.cc
在构建中添加实现
如果您在使用 Bazel 构建安卓应用,那么需要添加 android_extended_ops_group1 或 android_extended_ops_group2 作为构建目标。同时也需要包含里面所有的 .cc 文件。如果在构建中抛出没有头文件的异常,那么您可以添加 android_extended_ops作为构建目标。
如果您使用 makefile 为 iOS 或 Raspberry Pi 等设备构建应用,那么请到 tensorflow/contrib/makefile/tf_op_files.txt 添加相关的实现文件。
