操作语义
本文档介绍了在 ComputationBuilder 接口中定义的操作语义。通常来说,这些操作与 xla_data.proto 中 RPC 接口所定义的操作是一一对应的。
关于术语:广义数据类型 XLA 处理的是一个 N - 维数组,其元素均为某种数据类型(如 32 位浮点数)。在本文档中,数组 表示任意维度的数组。为方便起见,有些特例使用人们约定俗成的更具体和更熟悉的名称;比如,1 维数组称为向量,2 维数组称为矩阵。
BatchNormGrad
算法详情参见 ComputationBuilder::BatchNormGrad 和 batch normalization 原始论文。
计算 batch norm 的梯度
`BatchNormGrad(operand, scale, mean, variance, grad_output, epsilon, feature_index)`
| 类型 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待归一化的 n 维数组 (x) |
scale |
ComputationDataHandle |
1 维数组 (\(\gamma\)) |
mean |
ComputationDataHandle |
1 维数组 (\(\mu\)) |
variance |
ComputationDataHandle |
1 维数组 (\(\sigma^2\)) |
grad_output |
ComputationDataHandle |
传入 BatchNormTraining 的梯度(\( \nabla y\)) |
epsilon |
float |
ε 值 (\(\epsilon\)) |
feature_index |
int64 |
operand 中的特征维数索引 |
对于特征维数中的每一个特征(feature_index 即 operand 中特征维度的索引),此操作计算 operand 的梯度、在所有其他维度上的 offset 和 scale。feature_index 必须是 operand 中特征维度的合法索引。
这三个梯度由以下公式定义(假设四维张量为 operand 和(l)是特征维的索引):
\( coefl = \frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (\nabla y{ijkl} * (x{ijkl} - \mul) / (\sigma^2{l}+\epsilon)) \)
\( \nabla x{ijkl} = \gamma{l} (1/\sqrt{\sigma^2_{l}+\epsilon}) [\nabla y{ijkl} - mean(\nabla y) - (x{ijkl} - \mu_{l}) * coef_l] \)
\( \nabla \betal = \sum{i=1}^m\sum{j=1}^w\sum{k=1}^h \nabla y_{ijkl} \)
\( \nabla \gammal = \sum{i=1}^m\sum{j=1}^w\sum{k=1}^h \nabla y{ijkl} * ((x{ijkl} - \mul) / \sqrt{\sigma^2{l}+\epsilon}) \)
输入 mean 和 variance 表示在批处理和空间维度上的矩值。
输出类型是包含三个句柄的元组:
| 输出 | 类型 | 语义 |
|---|---|---|
grad_operand |
ComputationDataHandle |
输入 operand 的梯度 (\( \nabla x\)) |
grad_scale |
ComputationDataHandle |
输入 scale 的梯度 (\( \nabla \gamma\)) |
grad_offset |
ComputationDataHandle |
输入 offset 的梯度 (\( \nabla \beta\)) |
BatchNormInference
算法详情参见 ComputationBuilder::BatchNormInference 和 batch normalization 原始论文。
在批处理和空间维度上归一化数组。
`BatchNormInference(operand, scale, offset, mean, variance, epsilon, feature_index)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待归一化的 n 维数组 |
scale |
ComputationDataHandle |
1 维数组 |
offset |
ComputationDataHandle |
1 维数组 |
mean |
ComputationDataHandle |
1 维数组 |
variance |
ComputationDataHandle |
1 维数组 |
epsilon |
float |
ε 值 |
feature_index |
int64 |
operand 中的特征维数索引 |
对于特征维数中的每一个特征(feature_index 即 operand 中特征维度的索引),此操作计算在所有其他维度上的均值和方差,以及使用均值和方差归一化 operand 中的每个元素。feature_index 必须是 operand 中特征维度的合法索引。
BatchNormInference 等价于在每批次中不计算 mean 和 variance 的情况下调用 BatchNormTraining。它使用 mean 和 variance 作为估计值。此操作的目的是减少推断中的延迟,因此命名为 BatchNormInference。
输出是一个 N 维的标准化数组,与输入 operand 的形状相同。
BatchNormTraining
算法详情参见 ComputationBuilder::BatchNormTraining 和 batch normalization 原始论文。
在批处理和空间维度上归一化数组。
`BatchNormTraining(operand, scale, offset, epsilon, feature_index)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待归一化的 N 维数组 normalized (x) |
scale |
ComputationDataHandle |
1 维数组 (\(\gamma\)) |
offset |
ComputationDataHandle |
1 维数组 (\(\beta\)) |
epsilon |
float |
Epsilon 值 (\(\epsilon\)) |
feature_index |
int64 |
operand 中的特征维数索引 |
对于特征维数中的每一个特征(feature_index 即 operand 中特征维度的索引),此操作计算在所有其他维度上的均值和方差,以及使用均值和方差归一化 operand 中的每个元素。feature_index 必须是 operand 中特征维度的合法索引。
该算法对 operand \(x\) 中的每批次数据(包含 w 和 h 的 m 元素作为空间维度的大小)按如下次序执行:
在特征维度中,对每个特征
l计算批处理均值 \(\mu_l\):
\(\mul=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h x_{ijkl}\)计算批处理方差 \(\sigma^2_l\):
\(\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2\)归一化、缩放和平移:
\(y_{ijkl}=\frac{\gammal(x{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon}}+\beta_l\)
ε 值,通常是一个很小的数字,以避免 divide-by-zero 错误
输出类型是一个包含三个 ComputationDataHandle 类型元素的元组:
| 输出 | 类型 | 语义 |
|---|---|---|
output |
ComputationDataHandle |
与输入 operand (y)具有相同形状的 N 维数组 |
batch_mean |
ComputationDataHandle |
1 维数组 (\(\mu\)) |
batch_var |
ComputationDataHandle |
1 维数组 (\(\sigma^2\)) |
输入 batch_mean 和 batch_var 表示使用上述公式在批处理和空间维度上计算的矩值。
BitcastConvertType
同样参见
ComputationBuilder::BitcastConvertType.
类似于 TensorFlow 中的 tf.bitcast,对输入数据的每个元素进行 bitcast 操作,从而转化为目标形状。维度必须匹配,且转换是一对一的;如 s32 元素通过 bitcast 操作转化为 f32。Bitcast 采用底层 cast 操作,所以不同浮点数表示法的机器会产生不同的结果。
`BitcastConvertType(operand, new_element_type)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
D 维,类型为 T 的数组 |
new_element_type |
PrimitiveType |
类型 U |
operand 和 目标形状的维度必须匹配。源和目标元素类型的位宽必须一致。源和目标元素类型不能是元组。
广播(Broadcast)
另请参阅 ComputationBuilder::Broadcast。
通过在数组中复制数据来增加其维度。
`Broadcast(operand, broadcast_sizes)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待复制的数组 |
broadcast_sizes |
ArraySlice<int64> |
新维度的形状大小 |
新的维度被插入在操作数(operand)的左侧,即,若 broadcast_sizes 的值为 {a0, ..., aN},而操作数(operand)的维度形状为 {b0, ..., bM},则广播后输出的维度形状为 {a0, ..., aN, b0, ..., bM}。
新的维度指标被插入到操作数(operand)副本中,即
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
比如,若 operand 为一个值为 2.0f 的标量,且 broadcast_sizes 为 {2, 3},则结果形状为 f32[2, 3] 的一个数组,且它的所有元素的值都为 2.0f。
调用(Call)
另请参阅 ComputationBuilder::Call。
给定参数情况下,触发计算。
`Call(computation, args...)`
| 参数 | 类型 | 语义 |
|---|---|---|
computation |
Computation |
类型为 T_0, T_1, ..., T_N ->S 的计算,它有 N 个任意类型的参数 |
args |
N 个 ComputationDataHandle 的序列 |
任意类型的 N 个 参数 |
参数 args 的数目和类型必须与计算 computation 相匹配。当然,没有参数 args 也是允许的。
钳制(Clamp)
另请参阅 ComputationBuilder::Clamp。
将一个操作数钳制在最小值和最大值之间的范围内。
`Clamp(min, operand, max)`
| 参数 | 类型 | 语义 |
|---|---|---|
min |
ComputationDataHandle |
类型为 T 的数组 |
operand |
ComputationDataHandle |
类型为 T 的数组 |
max |
ComputationDataHandle |
类型为 T 的数组 |
给定操作数,最小和最大值,如果操作数位于最小值和最大值之间,则返回操作数,否则,如果操作数小于最小值,则返回最小值,如果操作数大于最大值,则返回最大值。即 clamp(a, x, b) = min(max(a, x), b)。
输入的三个数组的维度形状必须是一样的。另外,也可以采用一种严格的广播形式,即 min 和/或 max 可以是类型为 T 的一个标量。
min 和 max 为标量的示例如下:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
折叠(Collapse)
将一个数组的多个维度折叠为一个维度。
`Collapse(operand, dimensions)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的数组 |
dimensions |
int64 矢量 |
T 的维度形状的依次连续子集 |
比如,令 v 为包含 24 个元素的数组:
let v = f32[4x2x3] {{{10, 11, 12}, {15, 16, 17}},
{{20, 21, 22}, {25, 26, 27}},
{{30, 31, 32}, {35, 36, 37}},
{{40, 41, 42}, {45, 46, 47}}};
// 折叠至一个维度,即只留下一个维度
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// 折叠两个较低维度,剩下两个维度
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] {{10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47}};
// 折叠两个较高维度,剩下两个维度
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] {{10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47}};
串连(Concatenate)
另请参阅 ComputationBuilder::ConcatInDim。
串连操作是将多个数组操作数合并成一个数组。输出数组与输入数组的秩必须是一样的(即要求输入数组的秩也要相同),并且它按输入次序包含了输入数组的所有元素。
`Concatenate(operands..., dimension)`
| 参数 | 类型 | 语义 |
|---|---|---|
operands |
N 个 ComputationDataHandle 的序列 |
类型为 T 维度为 [L0, L1, ...] 的 N 个数组。要求 N>=1 |
dimension |
int64 |
区间 [0, N) 中的一个整数值,令那些 operands 能够串连起来的维度名 |
除了 dimension 之外,其它维度都必须是一样的。这是因为 XLA 不支持 "不规则" 数组。还要注意的是,0-阶的标量值是无法串连在一起的(因为无法确定串连到底发生在哪个维度)。
1-维示例:
Concat({{2, 3}, {4, 5}, {6, 7}}, 0)
>>> {2, 3, 4, 5, 6, 7}
2-维示例:
let a = {
{1, 2},
{3, 4},
{5, 6},
};
let b = {
{7, 8},
};
Concat({a, b}, 0)
>>> {
{1, 2},
{3, 4},
{5, 6},
{7, 8},
}
图表:

Conditional
另请参阅 ComputationBuilder::Conditional.
`Conditional(pred, true_operand, true_computation, false_operand, false_computation)`
| 参数 | 类型 | 语义 |
|---|---|---|
pred |
ComputationDataHandle |
类型为 PRED 的标量 |
true_operand |
ComputationDataHandle |
类型为 T_0 的参数 |
true_computation |
Computation |
类型为 T_0 -> S 的计算 |
false_operand |
ComputationDataHandle |
类型为 T_1 的参数 |
false_computation |
Computation |
类型为 T_0 -> S 的计算 |
如果 pred 为 true,执行 true_computation,如果 pred 为 false,则返回结果。
true_computation 必须接受一个类型为 T_0 的单参数,并使用 true_operand 来调用,它们必须类型相同。 false_computation 必须接受一个类型为 T_1 的单参数,并使用 false_operand 来调用,它们必须类型相同。 true_computation 和 false_computation 的返回值的类型必须相同。
注意,根据 pred 的值,true_computation 和 false_computation 只能执行其中一个。
Conv (卷积)
另请参阅 ComputationBuilder::Conv。
类似于 ConvWithGeneralPadding,但是边缘填充(padding)方式比较简单,要么是 SAME 要么是 VALID。SAME 方式将对输入(lhs)边缘填充零,使得在不考虑步长(striding)的情况下输出与输入的维度形状一致。VALID 填充方式则表示没有填充。
ConvWithGeneralPadding (卷积)
另请参阅 ComputationBuilder::ConvWithGeneralPadding。
计算神经网络中使用的卷积。此处,一个卷积可被认为是一个 n-维窗口在一个 n-维底空间上移动,并对窗口的每个可能的位置执行一次计算。
| 参数 | 类型 | 语义 |
|---|---|---|
lhs |
ComputationDataHandle |
秩为 n+2 的输入数组 |
rhs |
ComputationDataHandle |
秩为 n+2 的内核权重数组 |
window_strides |
ArraySlice<int64> |
n-维内核步长数组 |
padding |
ArraySlice<pair<int64, int64>> |
n-维 (低, 高) 填充数据 |
lhs_dilation |
ArraySlice<int64> |
n-维左边扩张因子数组 |
rhs_dilation |
ArraySlice<int64> |
n-维右边扩张因子数组 |
设 n 为空间维数。lhs 参数是一个 n+2 阶数组,它描述底空间区域的维度。它被称为输入,其实 rhs 也是输入。在神经网络中,它们都属于输入激励。n+2 维的含义依次为:
batch: 此维中每个坐标表示执行卷积的一个独立输入z/depth/features: 基空间区域中的每个 (y,x) 位置都指定有一个矢量,由这个维度来表示spatial_dims: 描述了定义了底空间区域的那n个空间维度,窗口要在它上面移动
rhs 参数是一个 n+2 阶的数组,它描述了卷积过滤器/内核/窗口。这些维度的含义依次为:
output-z: 输出的z维度。input-z: 此维度的大小等于 lhs 参数的z维度的大小。spatial_dims: 描述了定义此 n-维窗口的那n个空间维度,此窗口用于在底空间上移动。
window_strides 参数指定了卷积窗口在空间维度上的步长。比如,如果步长为 3,则窗口只用放在第一个空间维度指标为 3 的倍数的那些位置上。
padding 参数指定了在底空间区域边缘填充多少个零。填充数目可以是负值 -- 这时数目绝对值表示执行卷积前要移除多少个元素。padding[0] 指定维度 y 的填充对子,padding[1] 指定的是维度 x 的填充对子。每个填充对子包含两个值,第一个值指定低位填充数目,第二个值指定高位填充数目。低位填充指的是低指标方向的填充,高位填充则是高指标方向的填充。比如,如果 padding[1] 为 (2,3),则在第二个空间维度上,左边填充 2 个零,右边填充 3 个零。填充等价于在执行卷积前在输入 (lhs) 中插入这些零值。
lhs_dilation 和 rhs_dilation 参数指定了扩张系数,分别应用于 lhs 和 rhs 的每个空间维度上。如果在一个空间维度上的扩张系数为 d,则 d-1 个洞将被插入到这个维度的每一项之间,从而增加数组的大小。这些洞被填充上 no-op 值,对于卷积来说表示零值。
输出形状的维度含义依次为:
batch: 和输入(lhs)具有相同的batch大小。z: 和内核(rhs)具有相同的output-z大小。spatial_dims: 每个卷积窗口的有效位置的值。
卷积窗口的有效位置是由步长和填充后的底空间区域大小所决定的。
为描述卷积到底干了什么,考虑一个二维卷积,为输出选择某个固定的 batch,z,y,x 坐标。则 (y,x) 是底空间区域中的某个窗口的一个角的位置(比如左上角,具体是哪个要看你如何编码其空间维度)。现在,我们从底空间区域中得到了一个二维窗口,其中每一个二维点都指定有一个一维矢量,所以,我们得到一个三维盒子。对于卷积过滤器而言,因为我们固定了输出坐标 z,我们也有一个三维盒子。这两个盒子具有相同的维度,所以我们可以让它们逐个元素地相乘并相加(类似于点乘)。最后得到输出值。
注意,如果 output-z 等于一个数,比如 5,则此窗口的每个位置都在输出的 z 维 上产生 5 个值。这些值对应于卷积过滤器的不同部分,即每个 output-z 坐标,都由一个独立的三维盒子生成。所以,你可以将其想象成 5 个分立的卷积,每个都用了不同的过滤器。
下面是一个考虑了填充和步长的二维卷积伪代码:
for (b, oz, oy, ox) { // 输出坐标
value = 0;
for (iz, ky, kx) { // 内核坐标和输入 z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if (底空间区域内的(iy, ix)是不在填充位置上的) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
ConvertElementType
另请参阅
ComputationBuilder::ConvertElementType.
与 C++ 中逐元素的 static_cast 类似,对输入数据的每个元素进行转换操作,从而转化为目标形状。维度必须匹配,且转换是一对一的;如 s32 元素通过 s32-to-f32 转换过程转换为 f32。
`ConvertElementType(operand, new_element_type)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
D 维类型为 T 的数组 |
new_element_type |
PrimitiveType |
类型 U |
操作数和目标形状的维度必须匹配。源和目标元素类型不能是元组。
一个 T=s32 到 U=f32 的转换将执行标准化的 int-to-float 转化过程,如 round-to-nearest-even。
注意:目前没有指定精确的 float-to-int 和 visa-versa 转换,但是将来可能作为转换操作的附加参数。不是所有的目标都实现了所有可能的转换。
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
CrossReplicaSum
另请参阅 ComputationBuilder::CrossReplicaSum。
跨多个副本(replica)的求和。
`CrossReplicaSum(operand)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
跨多个副本待求和的数组。 |
输出的维度形状与输入形状一样。比如,如果有两个副本,而操作数在这两个副本上的值分别为 (1.0, 2.5) 和 (3.0, 5.25),则此操作在两个副本上的输出值都是 (4.0, 7.75)。
计算 CrossReplicaSum 的结果需要从每个副本中获得一个输入,所以,如果一个副本执行一个 CrossReplicaSum 结点的次数多于其它副本,则前一个副本将永久等待。因此这些副本都运行的是同一个程序,这种情况发生的机会并不多,其中一种可能的情况是,一个 while 循环的条件依赖于输入的数据,而被输入的数据导致此循环在一个副本上执行的次数多于其它副本。
CustomCall
另请参阅 ComputationBuilder::CustomCall。
在计算中调用由用户提供的函数。
`CustomCall(target_name, args..., shape)`
| 参数 | 类型 | 语义 |
|---|---|---|
target_name |
string |
函数名称。一个指向这个符号名称的调用指令会被发出 |
args |
N 个 ComputationDataHandle 的序列 |
传递给此函数的 N 个任意类型的参数 |
shape |
Shape |
此函数的输出维度形状 |
不管参数的数目和类型,此函数的签名(signature)都是一样的。
extern "C" void target_name(void* out, void** in);
比如,如果使用 CustomCall 如下:
let x = f32[2] {1,2};
let y = f32[2x3] {{10, 20, 30}, {40, 50, 60}};
CustomCall("myfunc", {x, y}, f32[3x3])
myfunc 实现的一个示例如下:
extern "C" void myfunc(void* out, void** in) {
float (&x)[2] = *static_cast<float(*)[2]>(in[0]);
float (&y)[2][3] = *static_cast<float(*)[2][3]>(in[1]);
EXPECT_EQ(1, x[0]);
EXPECT_EQ(2, x[1]);
EXPECT_EQ(10, y[0][0]);
EXPECT_EQ(20, y[0][1]);
EXPECT_EQ(30, y[0][2]);
EXPECT_EQ(40, y[1][0]);
EXPECT_EQ(50, y[1][1]);
EXPECT_EQ(60, y[1][2]);
float (&z)[3][3] = *static_cast<float(*)[3][3]>(out);
z[0][0] = x[1] + y[1][0];
// ...
}
这个用户提供的函数不能有副作用,而且它的执行结果必须是确定的(即两次同样的调用不能有不同结果)。
注:用户函数的黑箱特点限制了编译器的优化潜力。所以,尽量使用原生的 XLA 操作来表示你的计算;只有在迫不得已的情况下才使用 CustomCall。
点乘(Dot)
另请参阅 ComputationBuilder::Dot。
`Dot(lhs, rhs)`
| 参数 | 类型 | 语义 |
|---|---|---|
lhs |
ComputationDataHandle |
类型为 T 的数组 |
rhs |
ComputationDataHandle |
类型为 T 的数组 |
此操作的具体语义由它的两个操作数的秩来决定:
| 输入 | 输出 | 语义 |
|---|---|---|
矢量 [n] dot 矢量 [n] |
标量 | 矢量点乘 |
矩阵 [m x k] dot 矢量 [k] |
矢量 [m] | 矩阵矢量乘法 |
矩阵 [m x k] dot 矩阵 [k x n] |
矩阵 [m x n] | 矩阵矩阵乘法 |
此操作执行的是 lhs 的最后一维与 rhs 的倒数第二维之间的乘法结果的求和。因而计算结果会导致维度的 "缩减"。lhs 和 rhs 缩减的维度必须具有相同的大小。在实际中,我们会用到矢量之间的点乘,矢量/矩阵点乘,以及矩阵间的乘法。
DotGeneral
另请参阅
ComputationBuilder::DotGeneral.
`DotGeneral(lhs, rhs, dimension_numbers)`
| 参数 | 类型 | 语义 |
|---|---|---|
lhs |
ComputationDataHandle |
类型为 T 的数组 |
rhs |
ComputationDataHandle |
类型为 T 的数组 |
dimension_numbers |
DotDimensionNumbers |
类型为 T 的数组 |
和点乘一样,但是对于 'lhs' 和 'rhs' 允许收缩和指定批处理维数。
| DotDimensionNumbers 成员 | 类型 | 语义 |
|---|---|---|
| 'lhs_contracting_dimensions' | repeated int64 | 'lhs' 转换维数 |
| 'rhs_contracting_dimensions' | repeated int64 | 'rhs' 转换维数 |
| 'lhs_batch_dimensions' | repeated int64 | 'lhs' 批处理维数 |
| 'rhs_batch_dimensions' | repeated int64 | 'rhs' 批处理维数 |
DotGeneral 根据 'dimension_numbers' 指定的维数进行转换操作,然后计算点积和。
与 'lhs' 和 'rhs' 有关的转换维数不需要相同,但是在 'lhs_contracting_dimensions' 和 'rhs_contracting_dimensions' 数组必须按照相同的顺序列出,同时具有相同的维数大小。且需要同时与 'lhs' 和 'rhs' 在同一个维度上。
以转换维数为例:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { {6.0, 12.0},
{15.0, 30.0} }
'lhs' 和 'rhs' 的批处理维数必须相同,在两个数组中必须以相同的顺序列出,同时维数大小必须相同。必须在合约和非合约/非批次维度之前订阅。
批处理维数的例子(批处理大小为 2,2x2 矩阵):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| Input | Output | Semantics |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | batch matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | batch matmul |
由此得出的结果维数是从批处理维度开始,然后是 lhs 非收缩/非批处理维数,最后是 rhs 非收缩/非批处理维数。
DynamicSlice
另请参阅 ComputationBuilder::DynamicSlice.
DynamicSlice从动态 start_indices 输入数组中提取子数组。size_indices 为每个维度的切片大小,它在每个维度上指定了切片范围:[start, start + size)。start_indices 的秩必须为 1,且维数大小等于 operand 的秩。
注意:当前实现未定义切片索引越界(错误的运行时生成的'start_indices')的情况。
`DynamicSlice(operand, start_indices, size_indices)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的 N 维数组 |
start_indices |
ComputationDataHandle |
N 个整数组成的秩为 1 的数组,其中包含每个维度的起始切片索引。值必须大于等于0 |
size_indices |
ArraySlice<int64> |
N 个整数组成的列表,其中包含每个维度的切片大小。值必须大于 0,且 start + size 必须小于等于维度大小,从而避免封装维数大小的模运算 |
1 维示例如下:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let s = {2}
DynamicSlice(a, s, {2}) produces:
{2.0, 3.0}
2 维示例如下:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
DynamicUpdateSlice
另请参见
ComputationBuilder::DynamicUpdateSlice.
DynamicUpdateSlice 是在输入数组 operand 上,通过切片 update 操作覆盖 start_indices 后生成的结果。update 的形状决定了更新后结果的子数组的形状。 start_indices 的秩必须为 1,且维数大小等于 operand 的秩。
注意:当前实现未定义切片索引越界(错误的运行时生成的'start_indices')的情况。
`DynamicUpdateSlice(operand, update, start_indices)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的 N 维数组 |
update |
ComputationDataHandle |
类型为 T 的包含切片更新的 N 维数组,每个维度的更新形状必须大于 0 ,且 start + update 必须小于维度大小,从而避免越界更新索引 |
start_indices |
ComputationDataHandle |
N 个整数组成的秩为 1 的数组,其中包含每个维度的起始切片索引。值必须大于等于0 |
1 维示例如下:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s) produces:
{0.0, 1.0, 5.0, 6.0, 4.0}
2 维示例如下:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s) produces:
{ {0.0, 1.0, 2.0},
{3.0, 12.0, 13.0},
{6.0, 14.0, 15.0},
{9.0, 16.0, 17.0} }
逐个元素的二元算术操作
另请参阅 ComputationBuilder::Add。
XLA 支持多个逐个元素的二元算术操作。
`Op(lhs, rhs)`
其中 Op 可以是如下操作之一:Add (加法), Sub (减法), Mul (乘法), Div (除法), Rem (余数), Max (最大值), Min (最小值), LogicalAnd (逻辑且), 或 LogicalOr (逻辑或)。
| 参数 | 类型 | 语义 |
|---|---|---|
lhs |
ComputationDataHandle |
左操作数:类型为 T 的数组 |
rhs |
ComputationDataHandle |
右操作数:类型为 T 的数组 |
当 Op 为 Rem 时,结果的符号与被除数一致,而结果的绝对值总是小于除数的绝对值。
不过,还是可以用如下接口来支持不同秩操作数的广播:
`Op(lhs, rhs, broadcast_dimensions)`
其中 Op 的含义同上。这种接口用于具有不同秩的数组之间的算术操作(比如将一个矩阵与一个矢量相加)。
逐个元素的比较操作
另请参阅 ComputationBuilder::Eq。
XLA 还支持标准的逐个元素的二元比较操作。注意:当比较浮点类型时,遵循的是标准的 IEEE 754 浮点数语义。
`Op(lhs, rhs)`
其中 Op 可以是如下操作之一:Eq (相等), Ne (不等), Ge (大于或等于), Gt (大于), Le (小于或等于), Lt (小于)。
| 参数 | 类型 | 语义 |
|---|---|---|
lhs |
ComputationDataHandle |
左操作数:类型为 T 的数组 |
rhs |
ComputationDataHandle |
右操作数:类型为 T 的数组 |
要想用广播来比较不同秩的数组,需要用到如下接口:
`Op(lhs, rhs, broadcast_dimensions)`
其中 Op 含义同上。这种接口应该用于不同阶的数组之间的比较操作(比如将一个矩阵加到一个矢量上)。
逐个元素的一元函数
ComputationBuilder 支持下列逐个元素的一元函数:
`Abs(operand)` 逐个元素的绝对值 x -> |x|。
`Ceil(operand)` 逐个元素的整数上界 x -> ⌈x⌉。
`Cos(operand)` 逐个元素的余弦 x -> cos(x)。
`Exp(operand)` 逐个元素的自然幂指数 x -> e^x。
`Floor(operand)` 逐个元素的整数下界 x -> ⌊x⌋。
`IsFinite(operand)` 测试 operand 的每个元素是否是有限的,即不是正无穷或负无穷,也不是 NaN。该操作返回一个 PRED 值的数组,维度形状与输入一致,数组中的元素当且仅当相应的输入是有限时为 true,否则为 false。
`Log(operand)` 逐个元素的自然对数 x -> ln(x)。
`LogicalNot(operand)` 逐个元素的逻辑非 x -> !(x)。
`Neg(operand)` 逐个元素取负值 x -> -x。
`Sign(operand)` 逐个元素求符号 x -> sgn(x),其中
$$\text{sgn}(x) = \begin{cases} -1 & x < 0\ 0 & x = 0\ 1 & x > 0 \end{cases}$$
它使用的是 operand 的元素类型的比较运算符。
`Tanh(operand)` 逐个元素的双曲正切 x -> tanh(x)。
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
函数的操作数 |
该函数应用于 operand 数组的每个元素,从而形成具有相同形状的数组。它允许操作数为标量(秩 0 )
收集
XLA 收集操作将一个输入张量的几个片(每个片在一个可能不同的运行时偏移量上)拼接成一个输出张量。
一般语义
也可以在 ComputationBuilder::Gather 进行查阅。更直观的描述,请参阅下面的“非正式描述”部分。
`gather(operand, gather_indices, output_window_dims, elided_window_dims, window_bounds, gather_dims_to_operand_dims)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
我们收集的张量。 |
gather_indices |
ComputationDataHandle |
张量,包含切片的起始指数,我们将它们拼接输出到张量中。 |
index_vector_dim |
int64 |
包含起始索引 gather_indices 中的维度。 |
output_window_dims |
ArraySlice<int64> |
输出形状中的一组维度,即 windows 维度(定义如下)。并非所有窗口维度都可能出现在输出形状中。 |
elided_window_dims |
ArraySlice<int64> |
不存在于输出形状中的 window dimensions。对于 elided_window_dims 中的所有 i,window_bounds[i] 必须是 1。 |
window_bounds |
ArraySlice<int64> |
window_bounds[i] 是窗口维度 i 的边界。这包括显式地作为输出形状的一部分的窗口尺寸(通过 output_window_dims)和被省略的窗口维度(通过 elided_window_dims)。 |
gather_dims_to_operand_dims |
ArraySlice<int64> |
从 gather_indices 中的聚集索引到操作数索引的维度映射(数组被解释为将 i 映射为到 gather_dims_to_operand_dims[i])。它必须是一对一和全部的。 |
对于输出张量中的每一个索引 Out,我们计算两件事(之后进行更精确的描述):
gather_indices.rank的索引值 ——1维度的gather_indices,给出了操作数张量中的一个切片的起始索引 operand slice,这些都是gather_indices.rank——1维度就是gather_indices中的所有维度,除了index_vector_dim。与操作数等级相同 window index 由
Out在output_window_dims处的维度组成,并根据elided_window_dims嵌入零。window index 是 operand slice 中元素的相对索引,它应该出现在索引
Out中。
输出是等级 output_window_dims.size + gather_indices.rank - 1 的张量。此外,作为简写,我们将 ArraySlice<int64> 类型的 output_gather_dims 定义为输出形状中的维度集合,而不是 output_window_dims 中的维度按照升序排列。例如,如果输出张量具有等级 5,则 output_window_dims 是 {2, 4},那么 output_gather_dims 是 {0, 1, 3}。
如果 index_vector_dim 和 gather_indices.rank 相等,我们隐式地认为 gather_indices 具有尾随的 1 维(即,如果 gather_indices 是形状 [6,7] 而且 index_vector_dim 是 2,那么我们隐式地认为 gather_indices 的形状为 [6,7,1])。
输出张量沿维数 i 的边界计算如下:
- 如果
i存在于output_gather_dims(例如,对于某些k来说,等于output_gather_dims[k]),那么我们从gather_indices.shape中选取相应的维度边界,跳过index_vector_dim(例如,如果k<index_vector_dim和gather_indices.shape.dims[k+1],则选择gather_indices.shape.dims[k],否则不选)。 - 如果
i存在于output_window_dims(例如,对于某些k来说,等于output_window_dims[k]),那么我们在计算elided_window_dims之后,就从window_bounds中选出相应的边界(即我们选择adjusted_window_bounds[k],其中adjusted_window_bounds为window_bounds,删除索引elided_window_dims处的边界)。
与 Out 索引对应的操作数索引 In 的计算如下:
- Let
G= {Out[k] forkinoutput_gather_dims}。使用G将向量S切片,以便S[i] =gather_indices[Combine(G,i)],将(A, b)插入位置为index_vector_dim的 b 插入到 A 中。注意,这个定义很好,如果G为空 —— 即,如果 ifG为空,则S=gather_indices。 - 创建一个索引,
S`in`, intooperand通过使用gather_dims_to_operand_dims映射(S`in` 是上述提到的 operand slice 起始索引)来将S散射成S。更确切地说:S`in`[gather_dims_to_operand_dims[k]] =S[k] ifk<gather_dims_to_operand_dims.size.S`in`[_] =0otherwise.
- 创建一个索引
W`in` intooperand通过将指数分散到Out中的输出窗口维度,按照elided_window_dims集合 (W`in` 是上述提及的 window index)。更确切地说:W` 在 `[window_dims_to_operand_dims(k)] =Out[k] ifk<output_window_dims.size(window_dims_to_operand_dims有如下定义)。- 另外
W` 在 `[_] =0。
In是W`in` +S`in`,是元素级加法。
window_dims_to_operand_dims 是域 [0, output_window_dims.size] 和范围 [0, operand.rank] \ elided_window_dims 的单调函数。因此,如果 output_window_dims.size 是 4,operand.rank 为 6 并且 elided_window_dims 为 {0, 2} 那么 window_dims_to_operand_dims 就是 {0→1, 1→3, 2→4, 3→5}。
非正式说明和实例
在下面的所有示例中,index_vector_dim 被设置为 gather_indices.rank - 1。index_vector_dim 的更有趣的值不会从根本上改变操作,但会使视觉表示更加繁琐。
为了直观地了解所有上述情况如何结合在一起,我们来看一个例子,它从一个 [16,11] 张量中收集 5 片形状为 [8,6] 的张量。切片到 [16,11] 张量中的位置可以表示为形状为 S64[2] 的索引向量,所有以 5 个位置的集合可以表示 S64[5,2] 张量。
集合操作的行为可以被描述为一个索引转换,采用 [G,W`0`,W`1`] 输出形状中的索引,并按以下方式将其映射到输入张量中的元素:

We first select an (X,Y) vector from the gather indices tensor using G. The element in the output tensor at index [G,W`0`,W`1`] is then the element in the input tensor at index [X+W`0`,Y+W`1`].
window_bounds 是 [8,6],它决定 W`0` 和 W`1` 的范围,这反过来决定切片的边界。
此集合操作充当批处理动态切片,G 作为批处理维度。
集合指数可能是多方面的,例如,使用形状 [4,5,2] 的 "gather indices" 张量的上述示例的一个更一般的版本可以翻译成这样的指数:

同样,这是一个批处理动态切片 G`0` 和 G`1`,窗口的边界仍然是 [8,6]。
XLA 中收集的数据操作概括了以上概述的非正式语义:
在最后一个示例中,我们可以配置输出形状中的哪些维度是窗口维度(上一个示例中包含
W`0`,W`1` 的维数)。输出集的维度(上一个示例中包含G`0`,G`1` 的维数)被定义为不是窗口的输出维度。输出形状中显式显示的输出窗口维数可能小于输入等级。这些“缺失”的维度显式地列为
elided_window_dims,必须有一个窗口为1。由于它们的窗口界为1,因此它们的唯一有效索引是0,而对它们进行赋值并不会引入歧义。从 "Gather Indices" 张量(最后一个示例中的(
X,Y)中提取的切片可能比输入张量 级别有更少的元素,并且一个明确的映射指示如何扩展索引,使其与输入具有相同的等级。
最后一个例子,我们使用(2)和(3)来实现 tf.gather_nd:

和往常一样,G`0` 和 G`1` 被用来从集合索引张量中分割一个起始索引,除了起始索引只有一个元素 X。类似的,只有一个输出窗口索引的值为 W`0`。但是,在作为索引运用到张量之前,这些索引被按照“聚集索引映射”(正式描述中的 gather_dims_to_operand_dims)和 “窗口映射”(形式描述中的 window_dims_to_operand_dims)将它们扩展为 [0,W`0`] 和 [X,0] 结果为 [X,W`0`]。换句话说,就是将输入索引 [G`0`,G`1`,W`0`] 映射为输出索引 [GatherIndices[G`0`,G`1`,0],X] 这给 tf.gather_nd 带来了语义化。
在这种情况下,window_bounds 是 [1,11]。直觉上这意味着集合索引张量中的每一个索引 X 都会选择整行,结果是所有这些行连在一起。
GetTupleElement
另请参阅 ComputationBuilder::GetTupleElement。
将索引添加到编译时常量的元组中。
该值必须是编译时常量,这样才可以通过形状推断确定结果值的类型。
概念上,这类似于 C++ 中的 std::get<int N>(t):
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // 推断出的形状匹配 s32.
Infeed
另请参阅 ComputationBuilder::Infeed.
`Infeed(shape)`
| 参数 | 类型 | 语义 |
|---|---|---|
shape |
Shape |
从 Infeed 接口读取数据的维度形状。此形状的数据布局必须与发送到设备上的数据相匹配;否则行为是未定义的 |
从设备的隐式 Infeed 流接口读取单个数据项,根据给定的形状和布局来进行解析,并返回一个此数据的 ComputationDataHandle。在一个计算中允许有多个 Infeed 操作,但这些 Infeed 操作之间必须是全序的。比如,下面代码中两个 Infeed 是全序的,因为在不同 while 循环之间有依赖关系。
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
不支持嵌套的元组形状。对于一个空的元组形状,Infeed 操作通常是一个 no-op,因而不会从设备的 Infeed 中读取任何数据。
注意:我们计划允许支持没有全序的多个 Infeed 操作,在这种情况下,编译器将提供信息,确定这些 Infeed 操作在编译后的程序中如何串行化。
映射(Map)
另请参阅 ComputationBuilder::Map。
`Map(operands..., computation)`
| 参数 | 类型 | 语义 |
|---|---|---|
operands |
N 个 ComputationDataHandle 的序列 |
类型为 T0..T{N-1} 的 N 个数组 |
computation |
Computation |
类型为T_0, T_1, ..., T_{N + M -1} -> S 的计算,有 N 个类型为 T 的参数,和 M 个任意类型的参数 |
dimensions |
int64 array |
映射维度的数组 |
static_operands |
M 个 ComputationDataHandle 的序列 |
任意类型的 M 个数组 |
将一个标量函数作用于给定的 operands 数组,可产生相同维度的数组,其中每个元素都是映射函数(mapped function)作用于相应输入数组中相应元素的结果,而 static_operands 是 computation 的附加输入。
此映射函数可以是任意计算过程,只不过它必须有 N 个类型为 T 的标量参数,和单个类型为 S 的输出。输出的维度与输入 operands 相同,只不过元素类型 T 换成了 S。
比如,Map(op1, op2, op3, computation, par1) 用 elem_out <-
computation(elem1, elem2, elem3, par1) 将输入数组中的每个(多维)指标映射产生输出数组。
填充(Pad)
另请参阅 ComputationBuilder::Pad。
`Pad(operand, padding_value, padding_config)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的数组 |
padding_value |
ComputationDataHandle |
类型为 T 的标量,用于填充 |
padding_config |
PaddingConfig |
每个维度的两端的填充量 (low, high) |
通过在数组周围和数组之间进行填充,可以将给定的 operand 数组扩大,其中 padding_value 和 padding_config 用于配置每个维度的边缘填充和内部填充的数目。
PaddingConfig 是 PaddingConfigDimension 的一个重复字段,它对于每个维度都包含有三个字段:edge_padding_low, edge_padding_high 和 interior_padding。edge_padding_low 和 edge_padding_high 分别指定了该维度上低端(指标为 0 那端)和高端(最高指标那端)上的填充数目。边缘填充数目可以是负值 — 负的填充数目的绝对值表示从指定维度移除元素的数目。interior_padding 指定了在每个维度的任意两个相邻元素之间的填充数目。逻辑上,内部填充应发生在边缘填充之前,所有在负边缘填充时,会从经过内部填充的操作数之上再移除边缘元素。如果边缘填充配置为 (0, 0),且内部填充值都是 0,则此操作是一个 no-op。下图展示的是二维数组上不同 edge_padding 和 interior_padding 值的示例。

Recv
另请参阅
ComputationBuilder::Recv.
`Recv(shape, channel_handle)`
| 参数 | 类型 | 语义 |
|---|---|---|
shape |
Shape |
要接收的数据的形状 |
channel_handle |
ChannelHandle |
发送/接收对的唯一标识 |
从另一台共享相同通道句柄的计算机的 Send 指令接收指定形状的数据,返回一个接收数据的 ComputationDataHandle。
客户端 Recv 操作的客户端 API 是同步通信。但是,指令内分解成 2 个 HLO 指令(Recv 和 RecvDone)用于异步数据传输。请参考 HloInstruction::CreateRecv 和 HloInstruction::CreateRecvDone
`Recv(const Shape& shape, int64 channel_id)`
分配资源从具有相同 channel_id 的 Send 指令接收数据。返回已分配资源的上下文,该上下文随后通过 RecvDone 指令等待数据传输完成。上下文是 {接收缓冲区 (形状), 请求标识符(U32)} 的元组,且只能用于 RecvDone 指令。
`RecvDone(HloInstruction context)`
给定一个由 Recv 指令创建的上下文,等待数据传输完成并返回接收的数据。
Reduce
另请参阅 ComputationBuilder::Reduce。
将一个归约函数作用于一个数组。
`Reduce(operand, init_value, computation, dimensions)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的数组 |
init_value |
ComputationDataHandle |
类型为 T 的标量 |
computation |
Computation |
类型为 T, T -> T的计算 |
dimensions |
int64 数组 |
待归约的未排序的维度数组 |
从概念上看,归约(Reduce)操作将输入数组中的一个或多个数组归约为标量。结果数组的秩为 rank(operand) - len(dimensions)。 init_value 是每次归约的初值,如果后端有需求也可以在计算中插入到任何地方。所以,在大多数情况下,init_value 应该为归约函数的一个单位元(比如,加法中的 0)。
归约函数的执行顺序是任意的,即可能是非确定的。因而,归约函数不应对运算的结合性敏感。
有些归约函数,比如加法,对于浮点数并没有严格遵守结合率。不过,如果数据的范围是有限的,则在大多数实际情况中,浮点加法已经足够满足结合率。当然,我们也可以构造出完全不遵守结合率的归约函数,这时,XLA 归约就会产生不正确或不可预测的结果。
下面是一个示例,对 1D 数组 [10, 11, 12, 13] 进行归约,归约函数为 f (即参数 computation),则计算结果为:
f(10, f(11, f(12, f(init_value, 13)))
但它还有其它很多种可能性,比如:
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(13,
init_value))))
下面是一段实现归约的伪代码,归约计算为求和,初值为 0。
result_shape <- 从 operand_shape 的维度中移除所有待归约的维度
# 遍历 result_shape 中的所有元素,这里,r 的数目等于 result 的秩
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# 初始化 result 的元素
result[r0, r1...] <- 0
# 遍历所有的归约维度
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# 用 operand 的元素的值来增加 result 中的元素的值
# operand 的元素的索引由所有的 ri 和 di 按正确的顺序构造而来
# (构造得到的索引用来访问 operand 的整个形状)
result[r0, r1...] += operand[ri... di]
下面是一个对 2D 数组(矩阵)进行归约的示例。其形状的秩为 2,0 维大小为 2,1 维大小为 3:

对 0 维或 1 维进行求和归约:

注意,两个归约结果都是一维数组。图中将一个显示为行,另一个显示为列,但这只是为了可视化效果。
下面是一个更复杂的 3D 数组的例子。它的秩为 3 ,形状为 (4,2,3)。为简单起见,我们让 1 到 6 这几个数字沿 0 维复制 4 份。

类似于二维的情况,我们可以只归约一个维度。如果我们归约第 0 维,我们得到一个二阶数组,它沿第 0 维的所有值会合并为一个标量:
| 4 8 12 |
| 16 20 24 |
如果我们归约第 2 维,结果仍然是一个二阶数组,沿第 2 维的所有值合并为一个标量:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
注意,输出中剩下的维度的顺序与它们在输入中的相对顺序保持一致,只不过维度的名称(数字)会发生变化,因为数组的秩发生了变化。
我们也可以归约多个维度。对 0 维和 1 维进行求和归约,将得到一个一维数组 | 20 28 36 |。
对这个三维数组的所有元素进行求和归约,得到一个标量 84。
ReducePrecision
另请参阅 ComputationBuilder::ReducePrecision。
当浮点数转换为低精度格式(比如 IEEE-FP16)然后转换回原格式时,值可能会发生变化,ReducePrecision 对这种变化进行建模。低精度格式中的指数(exponent)和尾数(mantissa)的位数目是可以任意指定的,不过不是所有硬件实现都支持所有的位大小。
`ReducePrecision(operand, mantissa_bits, exponent_bits)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
浮点类型 T 的数组 |
exponent_bits |
int32 |
低精度格式中的指数位数 |
mantissa_bits |
int32 |
低精度格式中的尾数位数 |
结果为类型为 T 的数组。输入值被舍入至与给定尾数位的数字最接近的那个值(采用的是"偶数优先"原则)。而超过指数位所允许的值域时,输入值会被视为正无穷或负无穷。NaN 值会保留,不过它可能会被转换为规范化的 NaN 值。
低精度格式必须至少有一个指数位(为了区分零和无穷,因为两者的尾数位都为零),且尾数位必须是非负的。指数或尾数位可能会超过类型 T;这种情况下,相应部分的转换就仅仅是一个 no-op 了。
ReduceWindow
另请参阅 ComputationBuilder::ReduceWindow。
将一个归约函数应用于输入多维数组的每个窗口内的所有元素上,输出一个多维数组,其元素个数等于合法窗口的元素数目。一个池化层可以表示为一个 ReduceWindow。
`ReduceWindow(operand, init_value, computation, window_dimensions, window_strides, padding)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的 N 维数组。这是窗口放置的底空间区域 |
init_value |
ComputationDataHandle |
归约的初始值。细节请参见 规约。 |
computation |
Computation |
类型为 T, T -> T的归约函数,应用于每个窗口内的所有元素 |
window_dimensions |
ArraySlice<int64> |
表示窗口维度值的整数数组 |
window_strides |
ArraySlice<int64> |
表示窗口步长值的整数数组 |
padding |
Padding |
窗口的边缘填充类型(Padding\:\:kSame 或 Padding\:\:kValid) |
下列代码和图为一个使用 ReduceWindow 的示例。输入是一个大小为 [4x6] 的矩阵,window_dimensions 和 window_stride_dimensions 都是 [2x3]。
// 创建一个归约计算(求最大值)
Computation max;
{
ComputationBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().ConsumeValueOrDie();
}
// 用最大值归约计算来创建一个 ReduceWindow 计算
ComputationBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input, *max,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);

在维度中,步长为 1 表示在此维度上两个相邻窗口间隔一个元素,为了让窗口互相不重叠,window_stride_dimensions 和 window_dimensions 应该要相等。下图给出了两种不同步长设置的效果。边缘填充应用于输入的每个维度,计算过程实际发生在填充之后的数组上。

归约函数的执行顺序是任意的,因而结果可能是非确定性的。所以,归约函数应该不能对计算的结合性太过敏感。更多细节,参见 Reduce 关于结合性的讨论。
Reshape
另请参阅 ComputationBuilder::Reshape 和 Collapse 操作。
变形操作(reshape)是将一个数组的维度变成另外一种维度设置。
`Reshape(operand, new_sizes)`
`Reshape(operand, dimensions, new_sizes)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的数组 |
dimensions |
int64 vector |
维度折叠的顺序 |
new_sizes |
int64 vector |
新维度大小的矢量 |
从概念上看,变形操作首先将一个数组拉平为一个一维矢量,然后将此矢量展开为一个新的形状。输入参数是一个类型为 T 的任意数组,一个编译时常量的维度指标数组,以及表示结果维度大小的一个编译时常量的数组。如果给出了 dimensions 参数,这个矢量中的值必须是 T 的所有维度的一个置换,其默认值为 {0, ..., rank - 1}。dimensions 中的维度的顺序是从最慢变化维(最主序)到最快变化维(最次序),按照这个顺序依次将所有元素折叠到一个维度上。new_sizes 矢量决定了输出数组的维度大小。new_sizes[0] 表示第 0 维的大小,new_sizes[1] 表示的是第 1 维的大小,依此类推。new_sizes 中的维度值的乘积必须等于 operand 的维度值的乘积。将折叠的一维数组展开为由 new_sizes 定义的多维数组时,new_sizes 中的维度的顺序也是最慢变化维(最主序)到最快变化维(最次序)。
比如,令 v 为包含 24 个元素的数组:
let v = f32[4x2x3] {{{10, 11, 12}, {15, 16, 17}},
{{20, 21, 22}, {25, 26, 27}},
{{30, 31, 32}, {35, 36, 37}},
{{40, 41, 42}, {45, 46, 47}}};
依次折叠:
let v012_24 = Reshape(v, {0,1,2}, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {0,1,2}, {8,3});
then v012_83 == f32[8x3] {{10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47}};
乱序折叠:
let v021_24 = Reshape(v, {1,2,0}, {24});
then v012_24 == f32[24] {10, 20, 30, 40, 11, 21, 31, 41, 12, 22, 32, 42,
15, 25, 35, 45, 16, 26, 36, 46, 17, 27, 37, 47};
let v021_83 = Reshape(v, {1,2,0}, {8,3});
then v021_83 == f32[8x3] {{10, 20, 30}, {40, 11, 21},
{31, 41, 12}, {22, 32, 42},
{15, 25, 35}, {45, 16, 26},
{36, 46, 17}, {27, 37, 47}};
let v021_262 = Reshape(v, {1,2,0}, {2,6,2});
then v021_262 == f32[2x6x2] {{{10, 20}, {30, 40},
{11, 21}, {31, 41},
{12, 22}, {32, 42}},
{{15, 25}, {35, 45},
{16, 26}, {36, 46},
{17, 27}, {37, 47}}};
作为特例,单元素数组和标量之间可以用变形操作相互转化。比如:
Reshape(f32[1x1] {{5}}, {0,1}, {}) == 5;
Reshape(5, {}, {1,1}) == f32[1x1] {{5}};
Rev (反转)
另请参阅 ComputationBuilder::Rev。
`Rev(operand, dimensions)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的数组 |
dimensions |
ArraySlice<int64> |
待反转的维度 |
反转操作是将 operand 数组沿指定的维度 dimensions 对元素的顺序反转,产生一个形状相同的数组。operand 数组的每个元素被存储在输出数组的变换后的位置上。元素的原索引位置在每个待倒置维度上都被反转了,得到其在输出数组中的索引位置(即,如果一个大小为 N 的维度是待倒置的,则索引 i 被变换为 N-i-i)。
Rev 操作的一个用途是在神经网络的梯度计算时沿两个窗口维度对卷积权重值进行倒置。
RngNormal
另请参阅 ComputationBuilder::RngNormal。
RngNormal 构造一个符合 $$(\mu, \sigma)$$ 正态随机分布的指定形状的随机数组。参数 mu 和 sigma 为 F32 类型的标量值,而输出形状为 F32 的数组。
`RngNormal(mean, sigma, shape)`
| 参数 | 类型 | 语义 |
|---|---|---|
mu |
ComputationDataHandle |
类型为 F32 的标量,指定生成的数的均值 |
sigma |
ComputationDataHandle |
类型为 F32 的标量,指定生成的数的标准差 |
shape |
Shape |
类型为 F32 的输出的形状 |
RngUniform
另请参阅 ComputationBuilder::RngUniform。
RngNormal 构造一个符合区间 $$[a,b)$$ 上的均匀分布的指定形状的随机数组。参数和输出形状可以是 F32、S32 或 U32,但是类型必须是一致的。此外,参数必须是标量值。如果 $$b <= a$$,输出结果与具体的实现有关。
`RngUniform(a, b, shape)`
| 参数 | 类型 | 语义 |
|---|---|---|
a |
ComputationDataHandle |
类型为 T 的标量,指定区间的下界 |
b |
ComputationDataHandle |
类型为 T 的标量,指定区间的上界 |
shape |
Shape |
类型为 T 的输出的形状 |
Select
另请参阅
ComputationBuilder::Select.
基于 predicate 数组的值,从两个输入数组构造输出数组。
`Select(pred, on_true, on_false)`
| 参数 | 类型 | 语义 |
|---|---|---|
pred |
ComputationDataHandle |
类型为 PRED 的数组 |
on_true |
ComputationDataHandle |
类型为 T 的数组 |
on_false |
ComputationDataHandle |
类型为 T 的数组 |
数组 on_true 和 on_false 的形状必须相同。这也是输出数组的形状。数组 pred 必须与 on_true、 on_false具有相同的维度,且值为 PRED 类型。
对于 pred 的每个元素 P,当 P 值为 true 时,相应的输出值从 on_true 中获取,否则从 on_false 中获取。由于 broadcasting 限制,pred 可以是类型为 PRED 的标量。此时,当 pred 值为 true 时,输出数组为 on_true,否则为 on_false。
非标量 pred 的示例如下:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
标量 pred 的示例如下:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
支持元组之间的 Selections 操作。因此元组认为是标量类型。如果 on_true 和 on_false 为元组(必须形状相同),则 pred 必须是类型为 PRED 的标量。
SelectAndScatter
另请参阅 ComputationBuilder::SelectAndScatter。
这个操作可视为一个复合操作,它先在 operand 数组上计算 ReduceWindow,以便从每个窗口中选择一个数,然后将 source 数组散布到选定元素的指标位置上,从而构造出一个与 operand 数组形状一样的输出数组。二元函数 select 用于从每个窗口中选出一个元素,当调用此函数时,第一个参数的指标矢量的字典序小于第二个参数的指标矢量。如果第一个参数被选中,则 select 返回 true,如果第二个参数被选中,则返回 false。而且该函数必须满足传递性,即如果 select(a, b) 和 select(b, c) 都为 true,则 select(a, c) 也为 true。这样,被选中的元素不依赖于指定窗口中元素访问的顺序。
scatter 函数作用在输出数组的每个选中的指标上。它有两个标量参数:
- 输出数组中选中指标处的值
source中被放置到选中指标处的值
它根据这两个参数返回一个标量值,用于更新输出数组中选中指标处的值。最开始的时候,输出数组所有指标处的值都被设为 init_value。
输出数组与 operand 数组的形状相同,而 source 数组必须与 operand 上应用 ReduceWindow 之后的形状相同。 SelectAndScatter 可用于神经网络池化层中梯度值的反向传播。
`SelectAndScatter(operand, select, window_dimensions, window_strides, padding, source, init_value, scatter)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的数组,窗口在它上面滑动 |
select |
Computation |
类型为 T, T -> PRED 的二元计算,它被应用到每个窗口中的所有元素上;如果选中第一个元素返回 true,如果选中第二个元素返回 false |
window_dimensions |
ArraySlice<int64> |
表示窗口维度值的整数数组 |
window_strides |
ArraySlice<int64> |
表示窗口步长值的整数数组 |
padding |
Padding |
窗口边缘填充类型(Padding\:\:kSame 或 Padding\:\:kValid) |
source |
ComputationDataHandle |
类型为 T 的数组,它的值用于散布 |
init_value |
ComputationDataHandle |
类型为 T 的标量值,用于输出数组的初值 |
scatter |
Computation |
类型为 T, T -> T 的二元计算,应用于 source 的每个元素和它的目标元素 |
下图为 SelectAndScatter 的示例,其中 select 函数计算它的参数中的最大值。注意,当窗口重叠时,如图 (2) 所示,operand 的一个指标可能会被不同窗口多次选中。在此图中,值为 9 的元素被顶部的两个窗口(蓝色和红色)选中,从而二元加法函数 scatter 产生值为 8 的输出值(2+6)。

scatter 函数的执行顺序是任意的,因而可能会出现不确定的结果。所以,scatter 函数不应该对计算的结合性过于敏感。更多细节,参见 Reduce 一节中关于结合性的讨论。
Send
另请参阅 ComputationBuilder::Send。
`Send(operand, channel_handle)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待发送的数据(类型为 T 的数组) |
channel_handle |
ChannelHandle |
发送/接收 对的唯一标识符 |
将给定的 operand 数据发送到另一台计算机上共享相同通道句柄的 Recv 中。不返回任何数据。
与 Recv 操纵类似,Send 操作的客户端 API 为同步通信,并在内部分解为 2 个 HLO 指令(Send 和 SendDone)以使用异步数据传输。另请参阅 HloInstruction::CreateSend 和 HloInstruction::CreateSendDone。
`Send(HloInstruction operand, int64 channel_id)`
发起 operand 的异步传输过程,将数据传输到具有相同通道 id 的 Recv 指令分配的资源中。返回一个上下文,随后使用 SendDone 指令等待数据传输完成。上下文是 {operand (shape), request identifier
(U32)} 的二元组,且只能用于 SendDone 指令。
`SendDone(HloInstruction context)`
根据 Send 指令创建的上下文,等待数据传输完成。指令不返回任何数据。
Scheduling of channel instructions
每个通道的 4 个指令 (Recv, RecvDone, Send, SendDone) 的执行顺序如下。
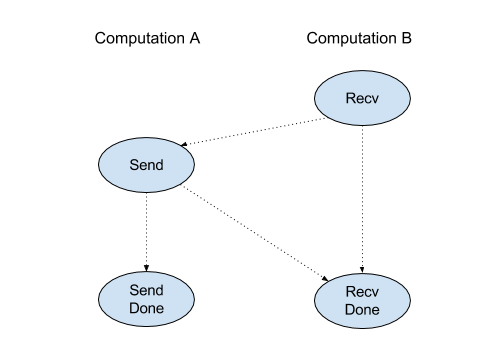
Recvhappens beforeSendSendhappens beforeRecvDoneRecvhappens beforeRecvDoneSendhappens beforeSendDone
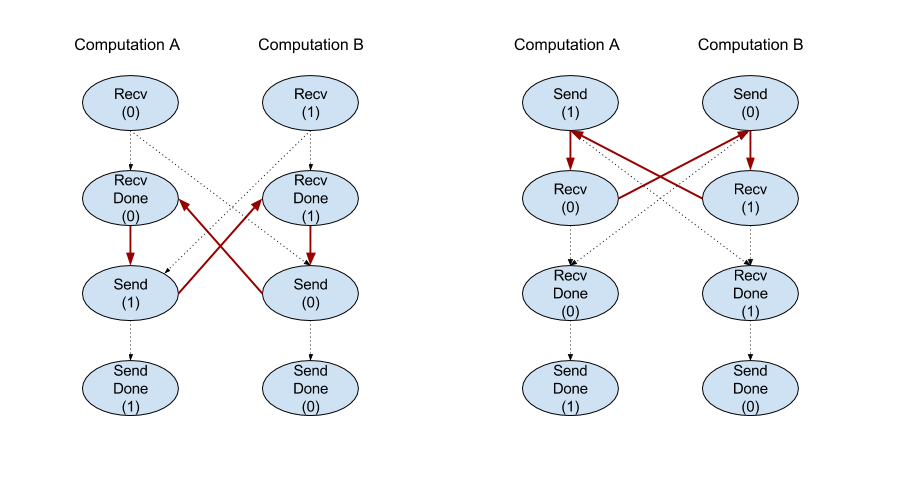
当后端编译器为通过通道指令进行通信的每一个计算生成一个线性调度时,在计算过程中不能有循环。例如,下面的调度会产生死循环。
Slice
另请参阅 ComputationBuilder::Slice。
Slice 用于从输入数组中提取出一个子数组。子数组与输入数组的秩相同,它的值在输入数组的包围盒中,此包围盒的维度和指标作为 slice 操作的参数而给出。
`Slice(operand, start_indices, limit_indices)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
类型为 T 的 N 维数组 |
start_indices |
ArraySlice<int64> |
N 个整数的数组,包含每个维度的切片的起始指标。值必须大于等于零 |
limit_indices |
ArraySlice<int64> |
N 个整数的数组,包含每个维度的切片的结束指标(不包含)。每个维度的结束指标必须严格大于其起始指标,且小于等于维度大小 |
1-维示例:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4}) produces:
{2.0, 3.0}
2-维示例:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
Sort
另请参阅 ComputationBuilder::Sort。
Sort 用于对输入数组中的元素进行排序。
`Sort(operand)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待排序数组 |
Transpose
`Transpose(operand)`
| 参数 | 类型 | 语义 |
|---|---|---|
operand |
ComputationDataHandle |
待转置的数组 |
permutation |
ArraySlice<int64> |
指定维度重排列的方式 |
Transpose 将 operand 数组的维度重排列,所以
∀ i . 0 ≤ i < rank ⇒ input_dimensions[permutation[i]] = output_dimensions[i]。
这等价于 Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions))。
Tuple
另请参阅 ComputationBuilder::Tuple。
一个元组(tuple)包含一些数据句柄,它们各自都有自己的形状。
概念上看,它类似于 C++ 中的 std::tuple:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
元组可通过 GetTupleElement 操作来解析(访问)。
While
另请参阅 ComputationBuilder::While。
`While(condition, body, init)`
| 参数 | 类型 | 语义 |
|---|---|---|
condition |
Computation |
类型为 T -> PRED 的计算,它定义了循环终止的条件 |
body |
Computation |
类型为 T -> T 的计算,它定义了循环体 |
init |
T |
condition 和 body 的参数的初始值 |
While 顺序执行循环体 body ,直到 condition 失败。这类似于很多语言中的 while 循环,不过,它有如下的区别和限制:
- 一个
While结点有一个类型为T的返回值,它是最后一次执行body的结果。 - 类型为
T的形状是由统计确定的,在整个迭代过程中,它都是保持不变的。 While结点之间不允许嵌套。这个限制可能会在未来某些目标平台上取消。
该计算的类型为 T 的那些参数使用 init 作为迭代的第一次计算的初值,并在接下来的迭代中由 body 来更新。
While 结点的一个主要使用安例是实现神经网络中的训练的重复执行。下面是一个简化版的伪代码,和一个表示计算过程的图。实际代码可以在 while_test.cc 中找到。此例中的 T 类型为一个 Tuple,它包含一个 int32 值,表示迭代次数,还有一个 vector[10],用于累加结果。它有 1000 次迭代,每一次都会将一个常数矢量累加到 result(1) 上。
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}

