Reading data
There are four methods of getting data into a TensorFlow program:
tf.dataAPI: Easily construct a complex input pipeline. (preferred method)- Feeding: Python code provides the data when running each step.
QueueRunner: a queue-based input pipeline reads the data from files
at the beginning of a TensorFlow graph.- Preloaded data: a constant or variable in the TensorFlow graph holds
all the data (for small data sets).
[TOC]
tf.data API
Feeding
Warning: "Feeding" is the least efficient way to feed data into a TensorFlow
program and should only be used for small experiments and debugging.
TensorFlow's feed mechanism lets you inject data into any Tensor in a
computation graph. A Python computation can thus feed data directly into the
graph.
Supply feed data through the feed_dict argument to a run() or eval() call
that initiates computation.
with tf.Session():
input = tf.placeholder(tf.float32)
classifier = ...
print(classifier.eval(feed_dict={input: my_python_preprocessing_fn()}))
An example using placeholder and feeding to train on MNIST data can be found
in
tensorflow/examples/tutorials/mnist/fully_connected_feed.py.
QueueRunner
A typical queue-based pipeline for reading records from files has the following stages:
- The list of filenames
- Optional filename shuffling
- Optional epoch limit
- Filename queue
- A Reader for the file format
- A decoder for a record read by the reader
- Optional preprocessing
- Example queue
Filenames, shuffling, and epoch limits
tf.train.string_input_producer
string_input_producer has options for shuffling and setting a maximum number
of epochs. A queue runner adds the whole list of filenames to the queue once
for each epoch, shuffling the filenames within an epoch if shuffle=True.
This procedure provides a uniform sampling of files, so that examples are not
under- or over- sampled relative to each other.
The queue runner works in a thread separate from the reader that pulls
filenames from the queue, so the shuffling and enqueuing process does not
block the reader.
File formats
Select the reader that matches your input file format and pass the filename
queue to the reader's read method. The read method outputs a key identifying
the file and record (useful for debugging if you have some weird records), and
a scalar string value. Use one (or more) of the decoder and conversion ops to
decode this string into the tensors that make up an example.
CSV files
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"])
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(
value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4])
with tf.Session() as sess:
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(1200):
# Retrieve a single instance:
example, label = sess.run([features, col5])
coord.request_stop()
coord.join(threads)
Each execution of read reads a single line from the file. The
decode_csv op then parses the result into a list of tensors. The
record_defaults argument determines the type of the resulting tensors and
sets the default value to use if a value is missing in the input string.
You must call tf.train.start_queue_runners to populate the queue before
you call run or eval to execute the read. Otherwise read will
block while it waits for filenames from the queue.
Fixed length records
Standard TensorFlow format
dataset = tf.data.TFRecordDataset(filename)
dataset = dataset.repeat(num_epochs)
# map takes a python function and applies it to every sample
dataset = dataset.map(decode)
To acomplish the same task with a queue based input pipeline requires the following code
(using the same decode function from the above example):
filename_queue = tf.train.string_input_producer([filename], num_epochs=num_epochs)
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
image,label = decode(serialized_example)
Preprocessing
You can then do any preprocessing of these examples you want. This would be any
processing that doesn't depend on trainable parameters. Examples include
normalization of your data, picking a random slice, adding noise or distortions,
etc. See
tensorflow_models/tutorials/image/cifar10/cifar10_input.py
for an example.
Batching
Example:
def read_my_file_format(filename_queue):
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue defines how big a buffer we will randomly sample
# from -- bigger means better shuffling but slower start up and more
# memory used.
# capacity must be larger than min_after_dequeue and the amount larger
# determines the maximum we will prefetch. Recommendation:
# min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
def read_my_file_format(filename_queue):
# Same as above
def input_pipeline(filenames, batch_size, read_threads, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example_list = [read_my_file_format(filename_queue)
for _ in range(read_threads)]
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch_join(
example_list, batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
You still only use a single filename queue that is shared by all the readers.
That way we ensure that the different readers use different files from the same
epoch until all the files from the epoch have been started. (It is also usually
sufficient to have a single thread filling the filename queue.)
- If you have more reading threads than input files, to avoid the risk that
you will have two threads reading the same example from the same file near
each other. - Or if reading N files in parallel causes too many disk seeks.
Creating threads to prefetch using QueueRunner objects
# Create the graph, etc.
init_op = tf.global_variables_initializer()
# Create a session for running operations in the Graph.
sess = tf.Session()
# Initialize the variables (like the epoch counter).
sess.run(init_op)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
while not coord.should_stop():
# Run training steps or whatever
sess.run(train_op)
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
sess.close()
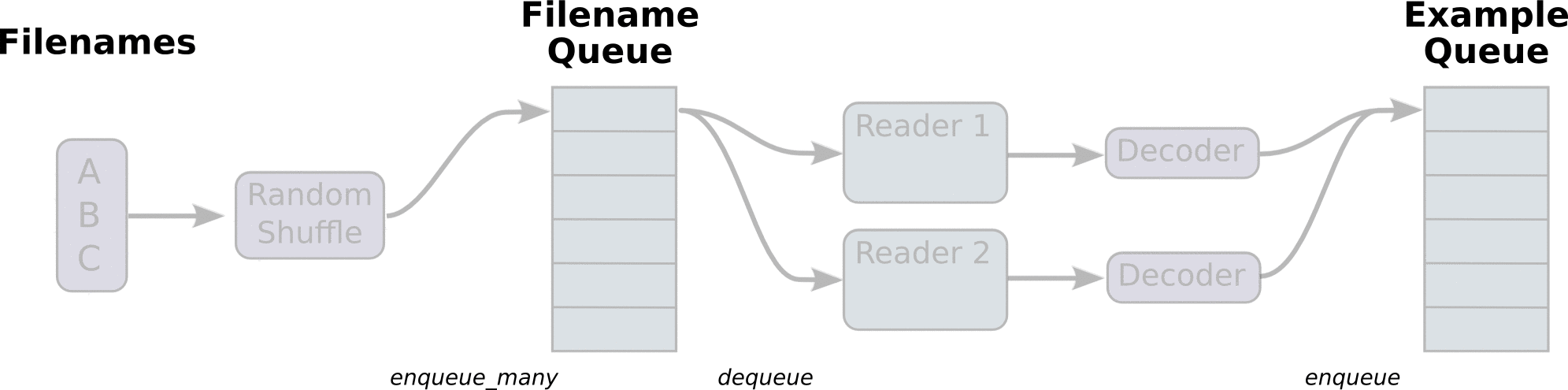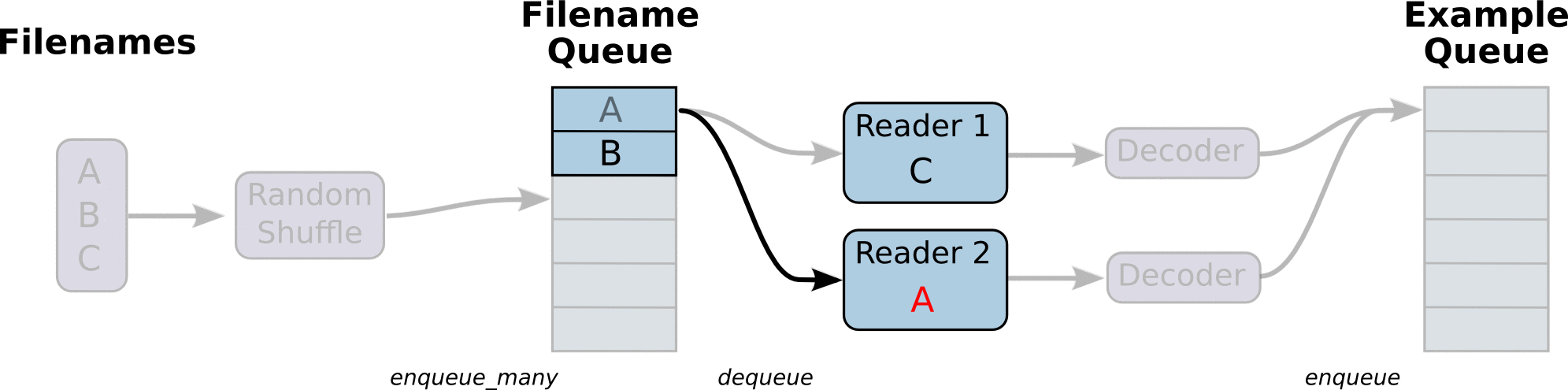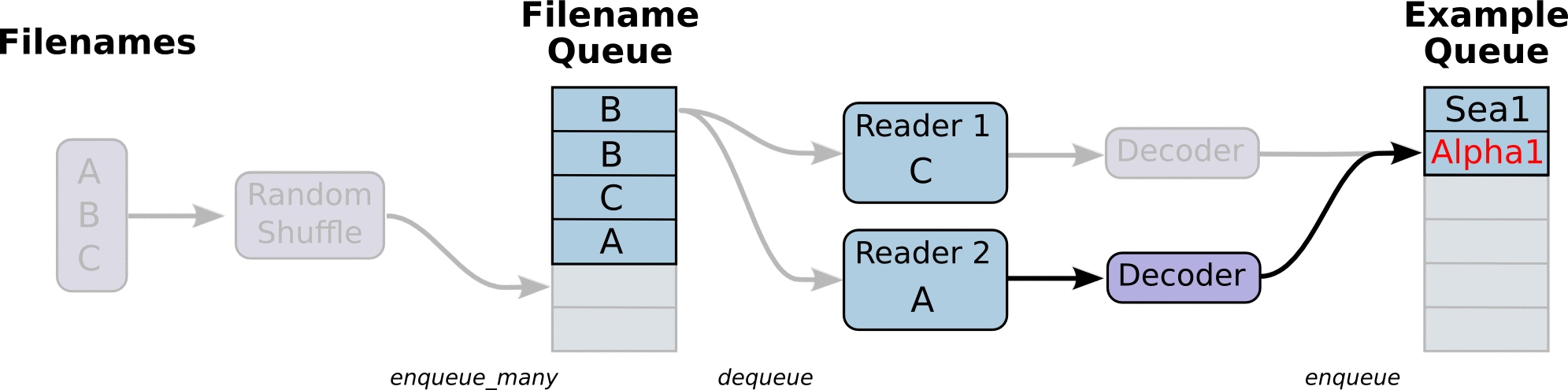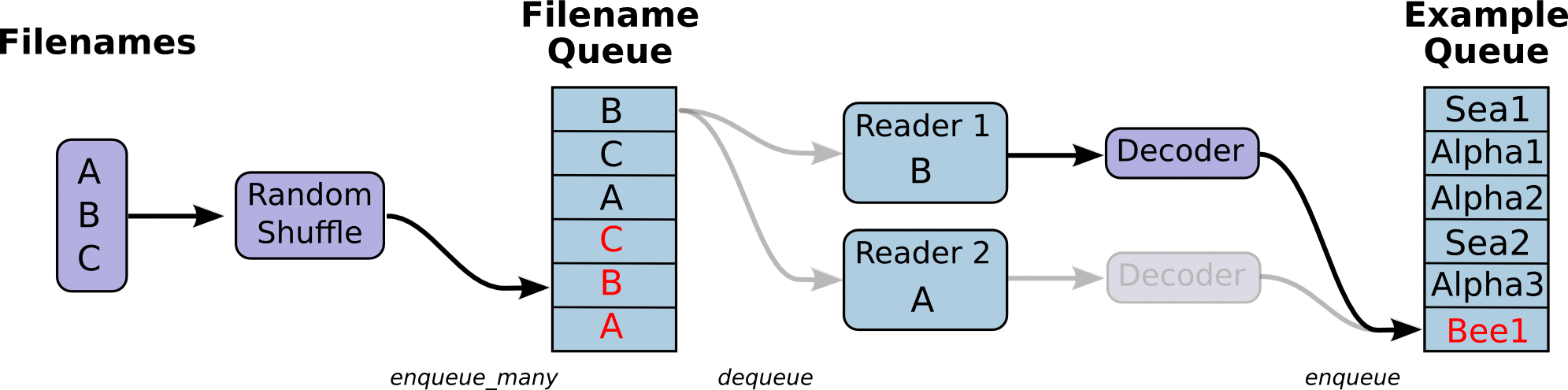
Aside: What is happening here?
First we create the graph. It will have a few pipeline stages that are
connected by queues. The first stage will generate filenames to read and enqueue
them in the filename queue. The second stage consumes filenames (using a
Reader), produces examples, and enqueues them in an example queue. Depending
on how you have set things up, you may actually have a few independent copies of
the second stage, so that you can read from multiple files in parallel. At the
end of these stages is an enqueue operation, which enqueues into a queue that
the next stage dequeues from. We want to start threads running these enqueuing
operations, so that our training loop can dequeue examples from the example
queue.
Aside: How clean shut-down when limiting epochs works
Imagine you have a model that has set a limit on the number of epochs to train
on. That means that the thread generating filenames will only run that many
times before generating an OutOfRange error. The QueueRunner will catch that
error, close the filename queue, and exit the thread. Closing the queue does two
things:
- Any future attempt to enqueue in the filename queue will generate an error.
At this point there shouldn't be any threads trying to do that, but this
is helpful when queues are closed due to other errors. - Any current or future dequeue will either succeed (if there are enough
elements left) or fail (with anOutOfRangeerror) immediately. They won't
block waiting for more elements to be enqueued, since by the previous point
that can't happen.
Filtering records or producing multiple examples per record
Instead of examples with shapes [x, y, z], you will produce a batch of
examples with shape [batch, x, y, z]. The batch size can be 0 if you want to
filter this record out (maybe it is in a hold-out set?), or bigger than 1 if you
are producing multiple examples per record. Then simply set enqueue_many=True
when calling one of the batching functions (such as shuffle_batch or
shuffle_batch_join).
Sparse input data
Preloaded data
This is only used for small data sets that can be loaded entirely in memory.
There are two approaches:
- Store the data in a constant.
- Store the data in a variable, that you initialize (or assign to) and then
never change.
Using a constant is a bit simpler, but uses more memory (since the constant is
stored inline in the graph data structure, which may be duplicated a few times).
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
...
To instead use a variable, you need to also initialize it after the graph has been built.
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initializer, trainable=False, collections=[])
input_labels = tf.Variable(label_initializer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_labels})
Setting trainable=False keeps the variable out of the
GraphKeys.TRAINABLE_VARIABLES collection in the graph, so we won't try and
update it when training. Setting collections=[] keeps the variable out of the
GraphKeys.GLOBAL_VARIABLES collection used for saving and restoring checkpoints.
An MNIST example that preloads the data using constants can be found in
tensorflow/examples/how_tos/reading_data/fully_connected_preloaded.py, and one that preloads the data using variables can be found in
tensorflow/examples/how_tos/reading_data/fully_connected_preloaded_var.py,
You can compare these with the fully_connected_feed and
fully_connected_reader versions above.
Multiple input pipelines
Commonly you will want to train on one dataset and evaluate (or "eval") on
another. One way to do this is to actually have two separate graphs and
sessions, maybe in separate processes:
- The training process reads training input data and periodically writes
checkpoint files with all the trained variables. - The evaluation process restores the checkpoint files into an inference
model that reads validation input data.
- The eval is performed on a single snapshot of the trained variables.
- You can perform the eval even after training has completed and exited.
