检查点
本文介绍如何保存和恢复编译有 Estimator 的 TensorFlow 模型。TensorFlow 提供两种模型格式:
- 检查点(checkpoints):这是一种依赖于创建模型代码的格式。
- SavedModel:这是一种与创建模型代码无关的格式。
示例代码
git clone https://github.com/tensorflow/models/
cd models/samples/core/get_started
本文中大部分代码片断都是在 premade_estimator.py 基础上少量修改的版本。
保存未训练完的模型
Estimators 自动将下列内容写到磁盘上:
- 检查点:训练过程中生成的不同版本的模型。
- 事件文件:包含一些用于 TensorBoard 可视化的信息
为指定 Estimator 存储信息的顶层目录,将其赋值给任何一个 Estimator 的构造函数的可选参数 model_dir。比如 ,下列代码将 model_dir 参数设置为 models/iris 目录:
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
hidden_units=[10, 10],
n_classes=3,
model_dir='models/iris')
假定你调用 Estimator 的 train 方法。比如:
classifier.train(
input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100),
steps=200)
如下列图表所示,第一次调用 train 将检查点和其它文件添加到 model_dir 目录中:
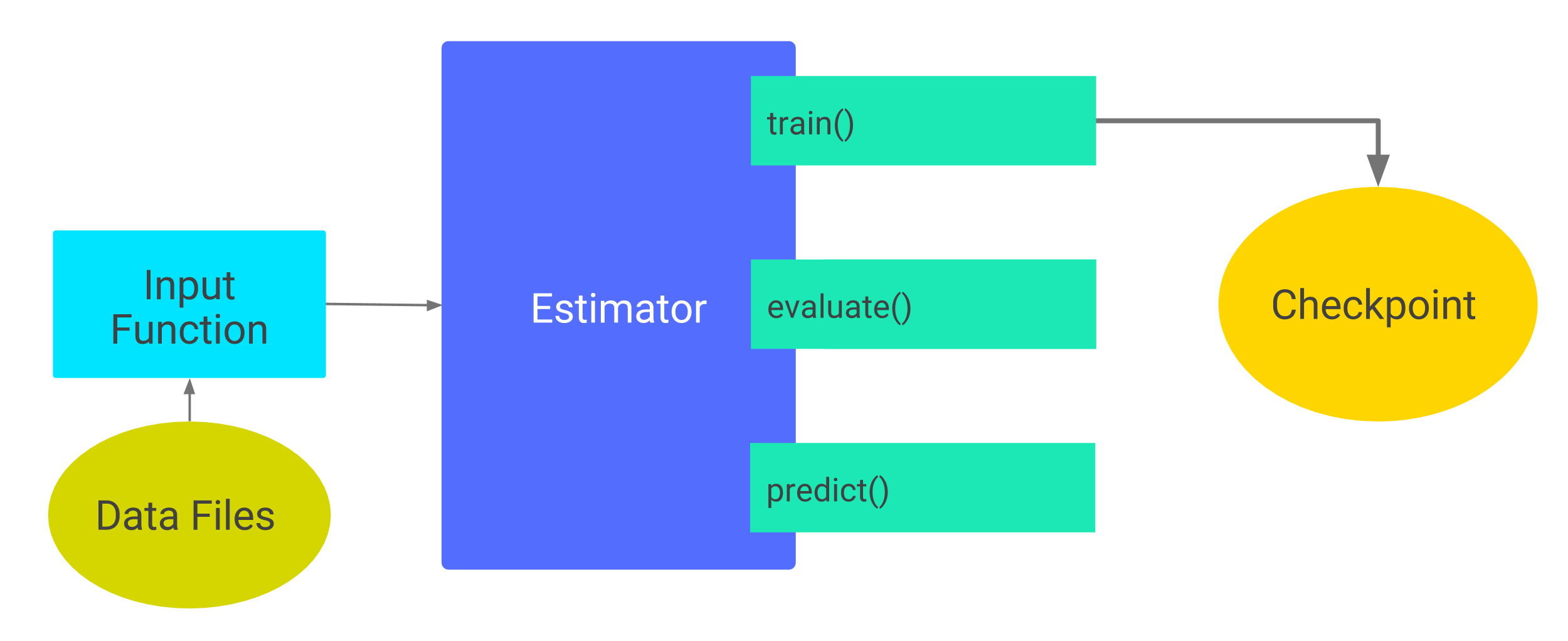
在一个类 UNIX 系统中,可用命令 ls 来查看 model_dir 目录中的对象:
$ ls -1 models/iris
checkpoint
events.out.tfevents.timestamp.hostname
graph.pbtxt
model.ckpt-1.data-00000-of-00001
model.ckpt-1.index
model.ckpt-1.meta
model.ckpt-200.data-00000-of-00001
model.ckpt-200.index
model.ckpt-200.meta
上面的 ls 命令显示,此 Estimator 在第 1 步(训练开始时)和第 200 步(训练结束时)生成了检查点。
默认检查点目录
如果你在一个 Estimator 构造函数中指定 model_dir 参数,此 Estimator 将检查点文件写到一个临时目录中,此目录由 Python 的 tempfile.mkdtemp 函数指定。比如,下面的 Estimator 构造函数并没有指定 model_dir 参数:
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
hidden_units=[10, 10],
n_classes=3)
print(classifier.model_dir)
tempfile.mkdtemp 函数会为你在操作系统中选择一个安全的临时目录。比如,在 macOS 操作系统中,一个典型的临时目录为:
/var/folders/0s/5q9kfzfj3gx2knj0vj8p68yc00dhcr/T/tmpYm1Rwa
检查点的保存频率
默认情况下, Estimator 会在 model_dir 目录中保存 检查点,并且采用如下策略:
- 每隔 10 分钟保存一个检查点(即 600 秒)。
- 当
train方法开始执行(即第一次循环)和执行结束(最后一次循环)时,会各保存一个检查点。 - 保留目录中最近 5 个检查点。
你可以用如下步骤改变上述默认策略:
tf.estimator.RunConfig- 当实例化 Estimator 时,将此
RunConfig对象传递给 Estimator 的config参数。
比如,下面的代码将检查点保存策略修改为每隔 20 分钟保存一次,且保留最近 10 个检查点:
my_checkpointing_config = tf.estimator.RunConfig(
save_checkpoints_secs = 20*60, # Save checkpoints every 20 minutes.
keep_checkpoint_max = 10, # Retain the 10 most recent checkpoints.
)
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
hidden_units=[10, 10],
n_classes=3,
model_dir='models/iris',
config=my_checkpointing_config)
恢复你的模型
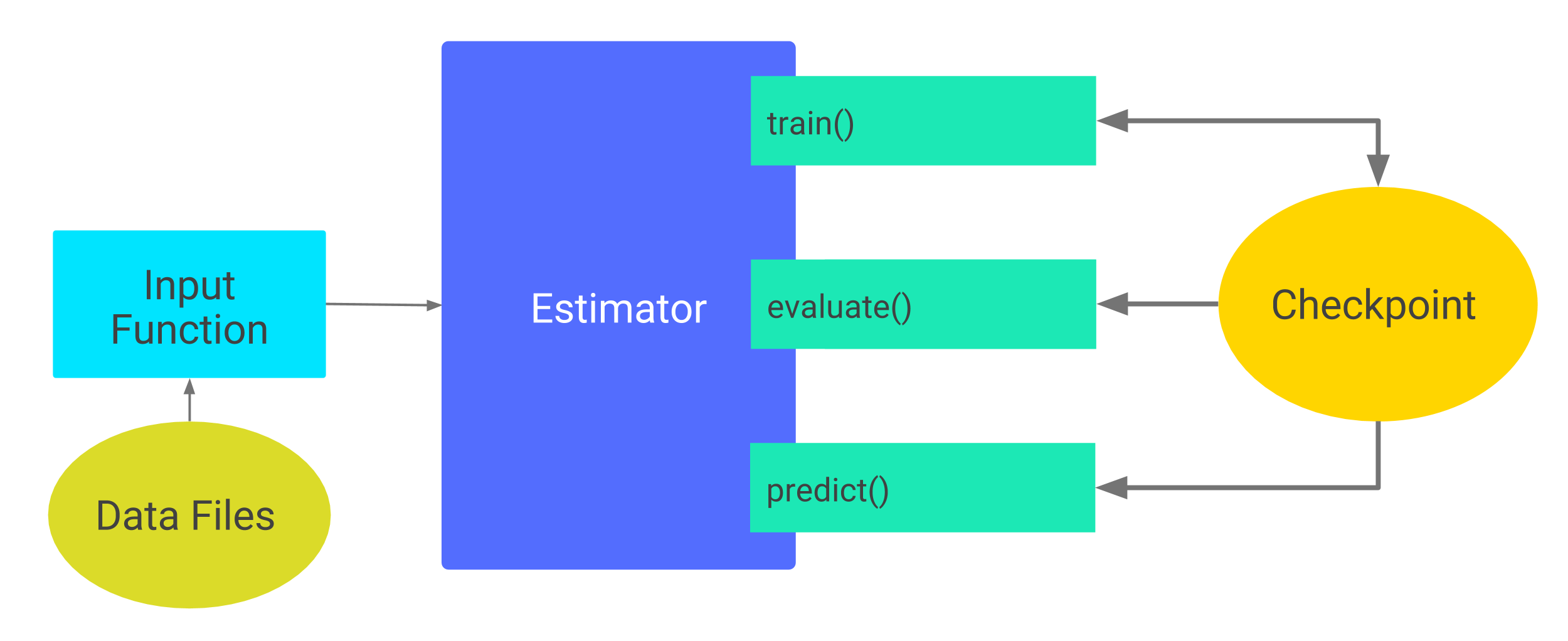
当第一次调用一个 Estimator 的 train 方法时,TensorFlow 会在 model_dir 目录中保存一个检查点。后续每调用一次 Estimator 的 train 、 evaluate 或 predict 方法,都会发生如下的行为:
- 创建定制化 Estimator
- 这个 Estimator 从最近的检查点中恢复出数据,用于初始化新模型的权重值。
换句话说,如下图所示,一旦检查点文件存在,TensorFlow 总会在你调用 train() 、 evaluation() 或 predict() 时重建模型。
避免不好的恢复
只有当模型与检查点兼容时,我们才可以从这个检查点中恢复出模型的状态。比如,假设你训练了一个称为 DNNClassifier 的 Estimator,它包含两个隐藏层,每个有 10 个结点:
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 10],
n_classes=3,
model_dir='models/iris')
classifier.train(
input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100),
steps=200)
经过训练之后(当然,也会同时在 models/iris 目录中创建检查点),假如你将每个隐藏层中的 10 个结点改成 20 个,然后再尝试恢复模型:
classifier2 = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
hidden_units=[20, 20], # 修改模型中的神经元个数
n_classes=3,
model_dir='models/iris')
classifier.train(
input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100),
steps=200)
因为检查点的状态与 classifier2 所描述的模型的状态不兼容,恢复模型会失败,错误信息如下:
...
InvalidArgumentError (see above for traceback): tensor_name =
dnn/hiddenlayer_1/bias/t_0/Adagrad; shape in shape_and_slice spec [10]
does not match the shape stored in checkpoint: [20]
当你在做实验时训练并比较版本稍有不同的模型时,记得保存创建每个 model_dir 的代码。比如,你可以为每个版本创建一个独立的 git 分支。这种分隔的做法可以保证你的检查点是可恢复的。
总结
检查点提供了一种容易的保存和恢复由 Estimator 生成的模型的自动化机制。
- 使用底层 TensorFlow API 来保存和恢复模型。
- 在 SavedModel 模式中导出和导入模型,这是一种语言无关、可恢复、可序列化格式。
