创建定制化 Estimator
下载及访问示例代码,请调用以下两个命令:
git clone https://github.com/tensorflow/models/
cd models/samples/core/get_started
在本文档中,我们将查看 custom_estimator.py。您可以使用以下命令运行它:
python custom_estimator.py
如果你感到不耐烦,可随时将 custom_estimator.py 与 premade_estimator.py 进行比较(对比),它们在同一目录中。
预制 vs. 定制化
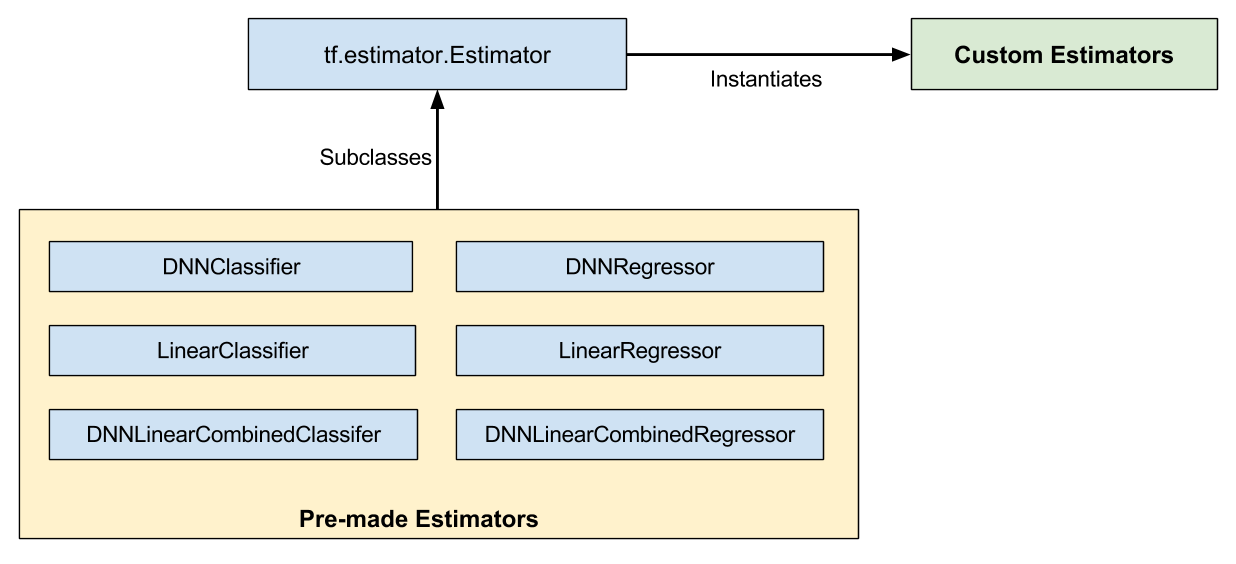
预制 Estimator 更加成熟。有时候您需要更多地控制 Estimator 的行为。这就是定制化 Estimator 出现的场景。您可以创建一个定制化 Estimator 来做任何事情。如果希望以某种不寻常的方式连接隐藏层,请编写定制化 Estimator。如果想要计算模型的唯一度量,请编写定制化 Estimator。基本上,如果想要针对特定问题优化的 Estimator,请编写定制化 Estimator。
一个函数模型(或者 model_fn)实现了 ML 算法,使用预制和定制化 Estimator 的唯一区别是:
- 预制 Estimator,已经有人为您编写了函数模型。
- 定制化 Estimator,您必须自己写函数模型。
您的函数模型可以实现范围更广的算法,定义各种隐藏层和度量。与输入函数一样,所有函数模型都必须接受一组标准的输入参数,并返回一组标准的输出值。就像输入函数可以利用数据集 API 一样,函数模型可以利用层 API 和 度量 API。
让我们看看如何使用定制化 Estimator 解决 Iris 问题。快速提醒 —— 这是我们尝试模仿虹膜模型的组织结构:
写一个输入函数
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# 将输入转换为数据集。
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# 随机播放,重复和批处理示例。
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# 返回管道读取的结束端。
return dataset.make_one_shot_iterator().get_next()
这个输入函数建立一个输入流水线,产生一批 (features, labels) 对,其中 features 是字典特征。
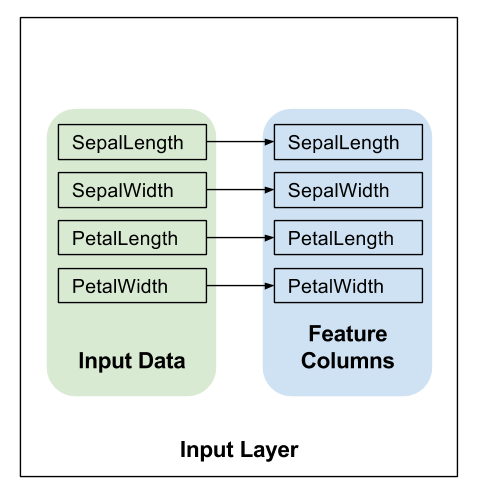
创建功能列
下面的代码为每个输入特征创建一个简单的 numeric_column ,表明输入特征值应该直接作为模型的输入:
# 特征列描述如何使用输入。
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
写一个模型函数
我们将使用的函数模型具有以下调用签名:
def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys
params): # Additional configuration
前两个参数是输入函数返回的功能部件和标签的批次:也就是说,features 和 labels 是您的模型将使用的数据的句柄。mode 参数指向调用方是否请求训练、预测或评估。
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
实现一个典型的函数模型,你必须做如下操作:
定义模型
基本的深度神经网络模型必须定义如下三个部分:
定义输出层
# 使用 `input_layer` 来应用特征列。
net = tf.feature_column.input_layer(features, params['feature_columns'])
上一行应用由特征列定义的转换,创建模型输入层。
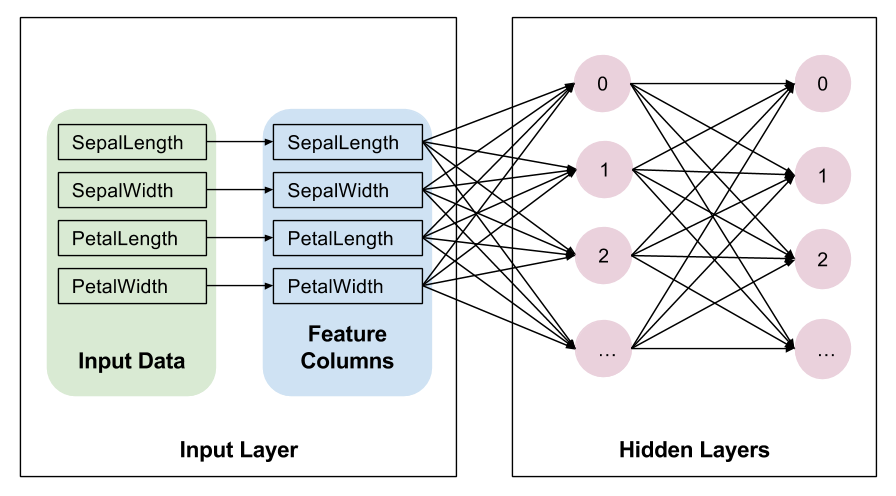
隐藏层
# 根据 'hidden_units' 参数构建隐藏层。
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
这里的变量 net 表示网络中当前的顶层。第一次迭代时,net 表示输入层。在每次迭代循环中,tf.layers.dense 创建一个新层,它使用 net 将上一层的输出作为输入。
创建两个隐藏层后,我们的网络如下所示。简而言之,该图不显示每层的所有单元。
输出层
# 计算 logits (每个 class 一个)。
logits = tf.layers.dense(net, params['n_classes'], activation=None)
这里 net 表示最后的隐藏层。因此,现在这个图层连接如下:
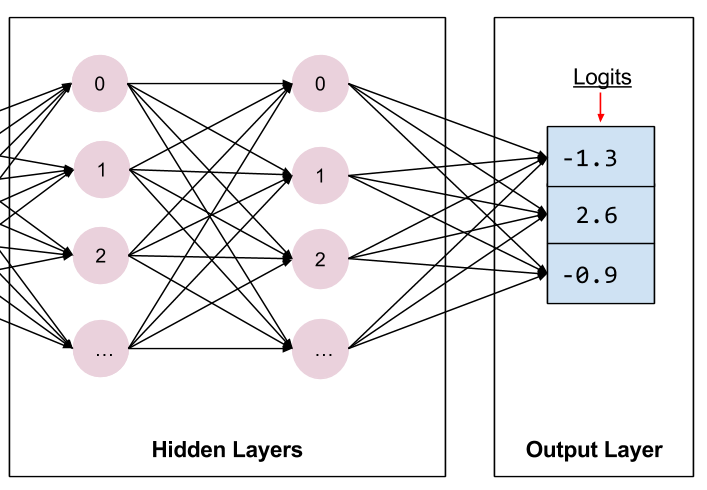
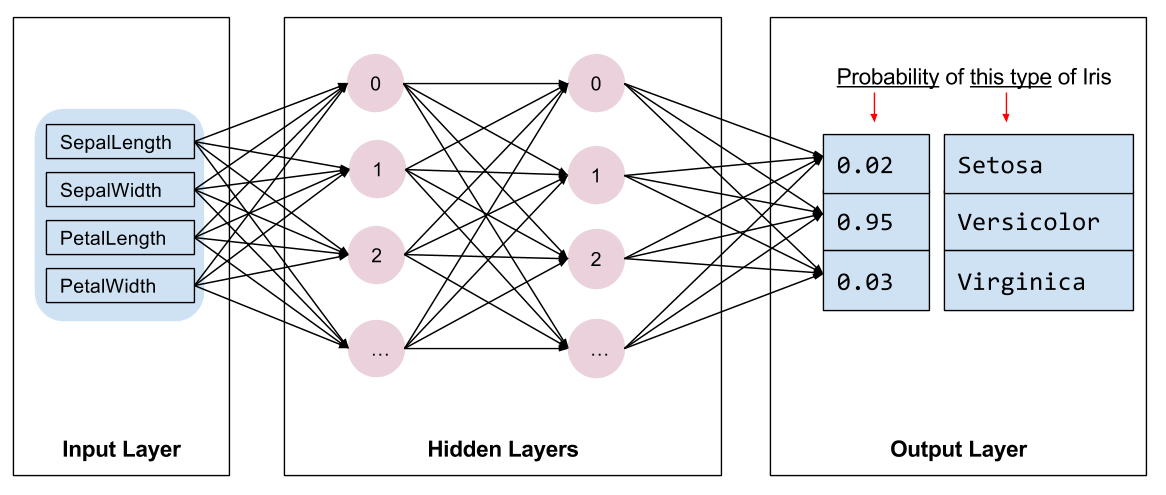
定义输出层时,units 参数指定输出的数量。因此,将 units 设置为 params['n_classes'],该模型会为每个类生成一个输出值。输出向量的每个元素都将包含得分或 logit,为关联的 Iris 类计算:Setosa、Versicolor 或 Virginica。
实现训练、评估、预测 {#modes}
创建函数模型的最后一步是编写分支代码实现预测、评估和训练。
当有人调用 Estimator 的 train 时,模型函数就会调用 evaluate 或者 predict 方法。就像这样回调模型的签名函数:
def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys, see below
params): # Additional configuration
关注第三个论点 — 模式。如下表所示,当某人调用 train,evaluate,或者 predict,Estimator 框架调用您的模型。函数模式的参数设置如下:
例如,假设您实例化一个自定义 Estimator 来生成一个 叫做 classifier 的对象。然后您执行以下调用:
classifier = tf.estimator.Estimator(...)
classifier.train(input_fn=lambda: my_input_fn(FILE_TRAIN, True, 500))
Estimator 框架调用您的函数模型,模式设置为 ModeKeys.TRAIN。
您的函数模型必须提供处理所有三个模式值的代码。对于每个模式值,您的代码必须返回 tf.estimator.EstimatorSpec,包含调用者的请求信息。让我们检查每一种模式。
预测
当 Estimator 的 predict 方法被调用时,model_fn 会接收到 mode = ModeKeys.PREDICT。在这种情况下,函数模型必须返回一个包含预测的 tf.estimator.EstimatorSpec。
在进行预测之前,模型必须经过训练。经过训练的模型存储在实例化 Estimator 时建立的 model_dir 目录中的磁盘上
为此模型生成预测的代码如下所示:
# 预测计算
predicted_classes = tf.argmax(logits, 1)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
在预测模式下,预测字典包含模型运行时返回的所有内容。

predictions 包含以下三个键值对:
-
class_ids保存表示模型类 的 id (0, 1, 或者 2),这个例子中最有可能出现的物种的预测。 -
probabilities保存三个概率 (在本例中 0.02、0.95 和 0.03)。 -
logit保存原始 logit 值 (在本例中 -1.3、2.6 和 -0.9)。
tf.estimator.Estimator.predict
计算损失
对于 training 和 evaluation 我们都需要计算模型的损失。这是将要被优化的目标。
tf.losses.sparse_softmax_cross_entropy
此函数返回整个批处理的平均值。
# 损失计算。
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
评估
当 Estimator 的 evaluate 方法被调用时,model_fn 接收到 mode = ModeKeys.EVAL。在这种情况下,模型函数必须返回一 tf.estimator.EstimatorSpec 包含模型损失和可选的一个或者更多的指标。
# metrics 指标计算。
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op')
loss,这是模型损失。eval_metric_ops,这是一个可选的度量字典。
所以我们将创建一个包含我们唯一度量标准的字典。如果我们计算了其他度量,我们会将它们添加为与其他键值对相同的字典。然后我们将在 eval_metric_ops 中传递该字典 tf.estimator.EstimatorSpec 的参数。代码如下:
metrics = {'accuracy': accuracy}
tf.summary.scalar('accuracy', accuracy[1])
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
训练
当调用 Estimator 的 train 方法时,使用 mode = ModeKeys.TRAIN 调用 model_fn。在这种情况下,模型函数必须返回包含损失和培训操作的 EstimatorSpec 。
以下是构建优化器的代码:
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
以下是训练模型的代码:
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
loss包含损失的函数值。train_op执行一个训练步骤。
下面是我们调用 EstimatorSpec 的代码:
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
模型功能现在已经完成了。
定制化 Estimator
通过 Estimator 基类指定定制化 Estimator,如下所示:
# 用两个 10 单元建立 2 个隐藏层的 DNN。
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
在这里 params 字典的作用与关键字相同。DNNClassifier 的参数,也就是说,params 字典允许您在不修改 model_fn 中代码的情况下配置您的 Estimator。
# 训练模型
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
TensorBoard
您可以在 TensorBoard 中查看定制化 Estimator 的训练结果。查看此报告,请从命令行启动 TensorBoard,如下所示:
# 将 PATH 替换为以 model_dir 形式传递的实际路径
tensorboard --logdir=PATH
然后在浏览器输入 http://localhost:6006 来打开 TensorBoard。
所有预制 Estimator 都会自动将大量信息记录到 TensorBoard 中。而对于定制化的 Estimators,TensorBoard 只提供一个默认日志(损失图)以及显式告诉 TensorBoard 进行日志记录的信息。对于您刚刚创建的定制化 Estimator,TensorBoard 生成以下内容:
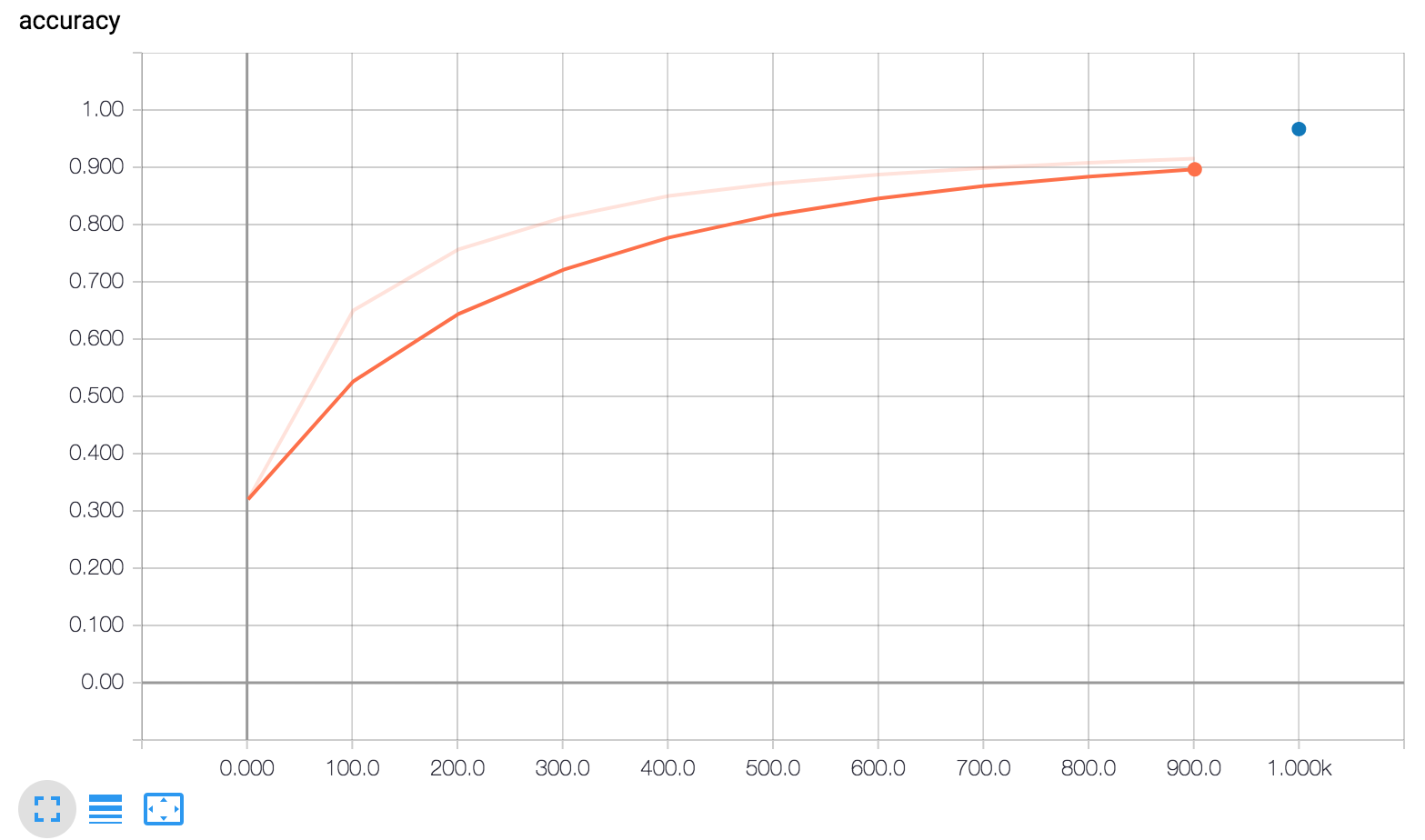
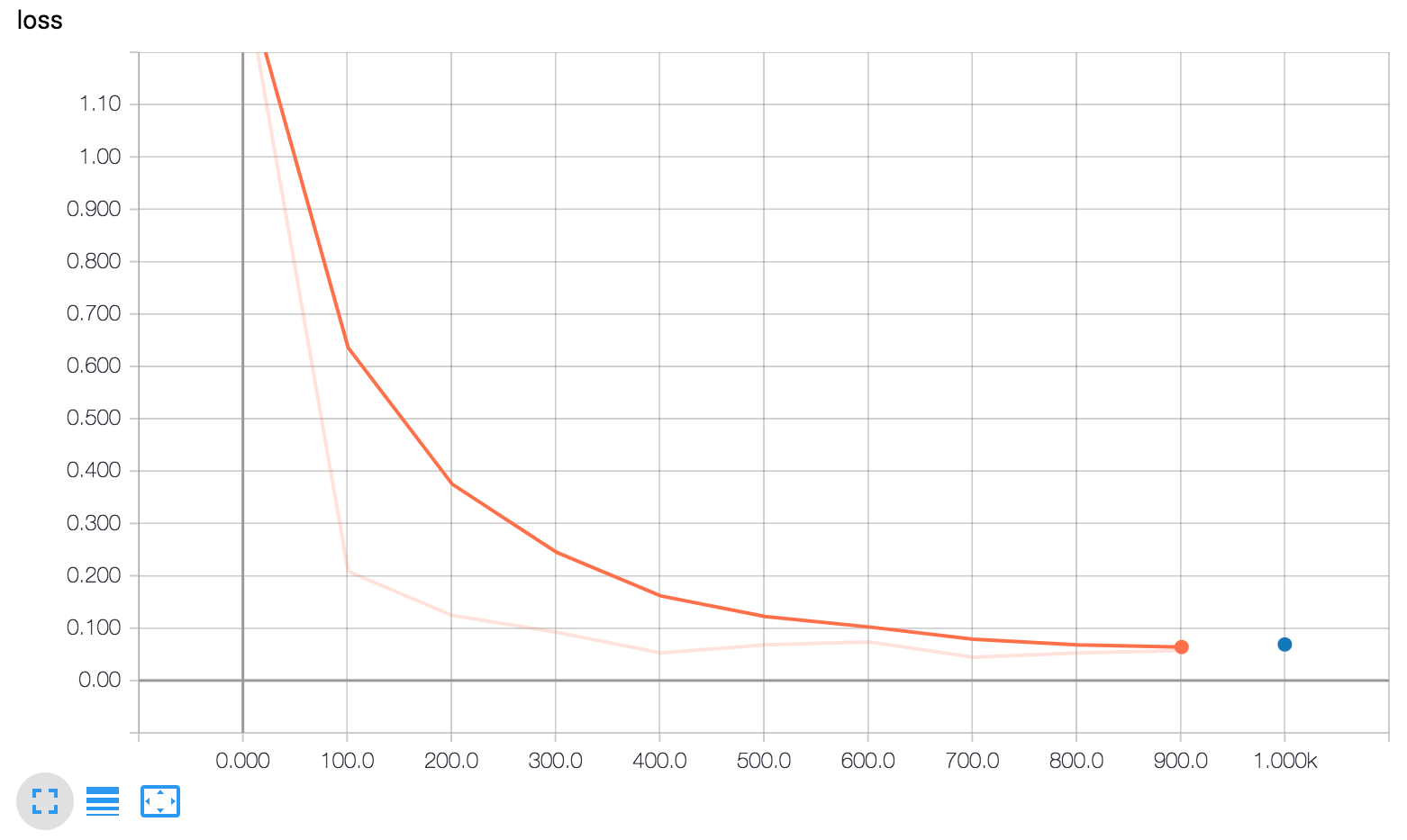
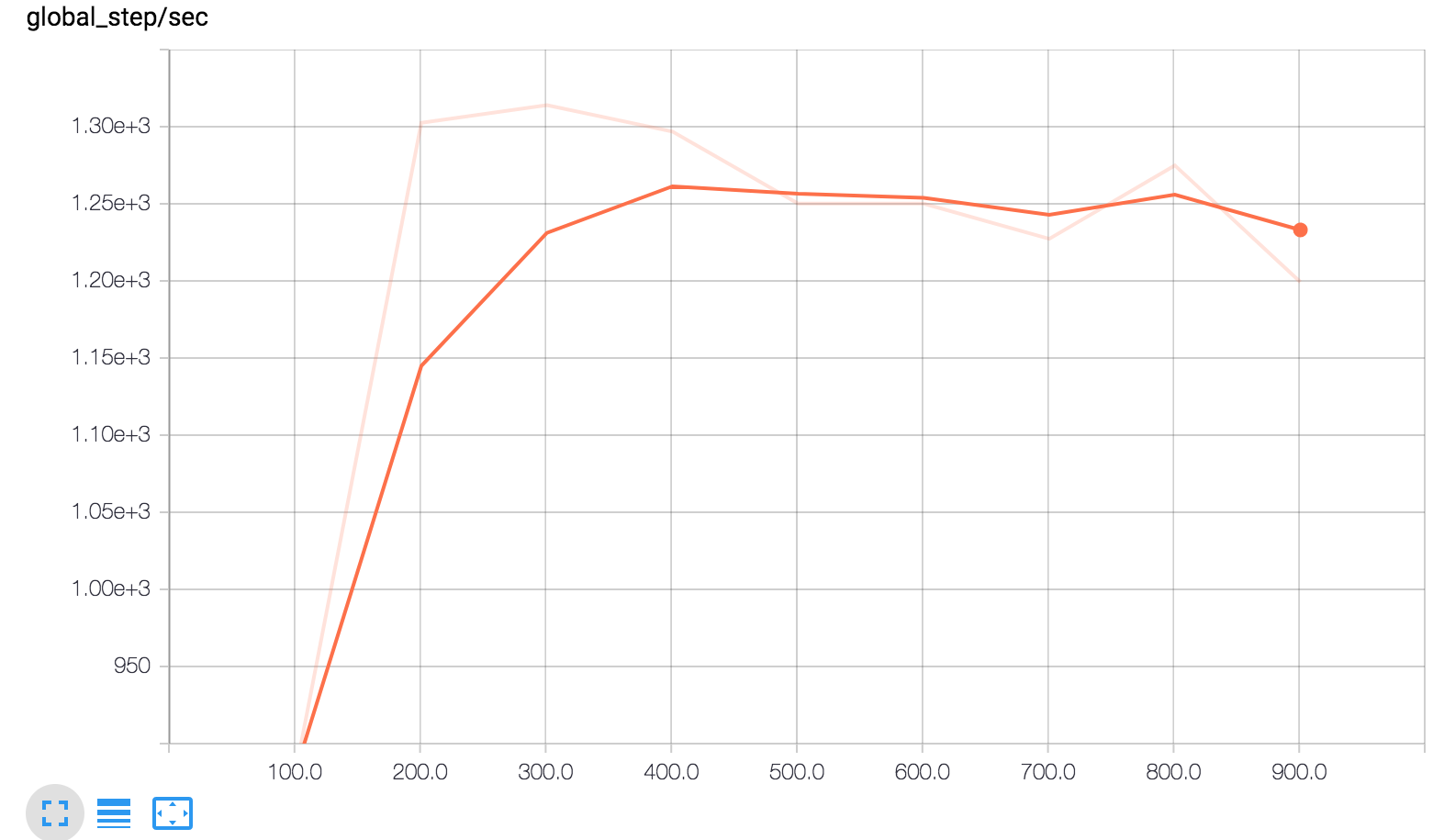
简而言之,下面三张图将告诉您:
global_step/sec: 显示多少批的性能指标(更新),我们每秒处理的作为训练模型)。
损失:损失报告。
准确性:准确性由以下两行记录:
eval_metric_ops={'my_accuracy': accuracy},在评估期间tf.summary.scalar('accuracy', accuracy[1]),在训练期间
这些 tensorboard 是向优化的 minimize 方法传递 global_step 的主要原因之一。没有它,模型就不能记录这些图的 x 坐标。
注意以下 my_accuracy 和 loss 图表:
- 橙色线代表训练。
- 蓝色点代表评估。
在训练期间,随着批次的处理,会定期记录摘要(橙色线),这就是为什么它会跨越 x 轴范围的图形。
相比之下,对于每个 evaluate 调用,评估只会在图形上产生一个点。这个点包含整个评估调用的平均值。这在图上没有宽度,因为它完全是从特定训练步骤的模型状态(从单个检查点)计算的。
如下图所示,您可以有选择地看到。使用左侧的控件禁用/启用报告。
总结
尽管预制 Estimator 是快速创建新模型的高效方式,通常您需要提供定制化 Estimator 额外的灵活性。幸运的是,预制和定制化遵循相同的编程模型。唯一的实际区别是您必须写一个模型用于自定义 Estimators 的函数,其他的所有内容都是相同的。
了解更多细节,请务必查看:
使用定制化 Estimator MINIST 的官方 TensorFlow 实现 ,
TensorFlow 官方模型库,其中包含了更多使用定制化 Estimator 的示例。
- TensorBoard 视频
- 介绍 TensorBoard。
- 底层 API 编程介绍
